
피벗 테이블이란, 데이터를 요약한 통계표라고 볼 수 있으며, 기존 데이터를 활용해서 새로운 테이블을 만든 것을 말한다.
같은 목적의 기능이지만 쓰는 형태는 달라 쓰다보면 헷갈리는 판다스 문법 3가지를 한 번에 비교해보려고 한다.
1. 크로스탭 crosstab
주로 두 개의 변수의 빈도수 구할때 사용하기 쉽다.
pd.crosstab(컬럼명1, 컬럼명2)
# 두 개의 변수의데이터 빈도수 구하기
df_p = pd.crosstab(df["제주 중분류"], df["월"])
df_p.iloc[:5][:5]
2. 피벗테이블 pivot_table
pd.pivot_table(data=df, index=컬럼1, <columns=컬럼2>, values=컬럼3)
columns는 스킵 가능
df.pivot_table(index=["alive","class"], values="fare")
group by 와 문법 비교해보기
# origin 별로 그룹화 하고 mpg 의 평균 구하기
# df.groupby("origin")[["mpg"]].mean()
pd.pivot_table(data=df, index="origin", values = "mpg")
# df.groupby(by=["origin","cylinders"])[["mpg"]].mean().unstack()
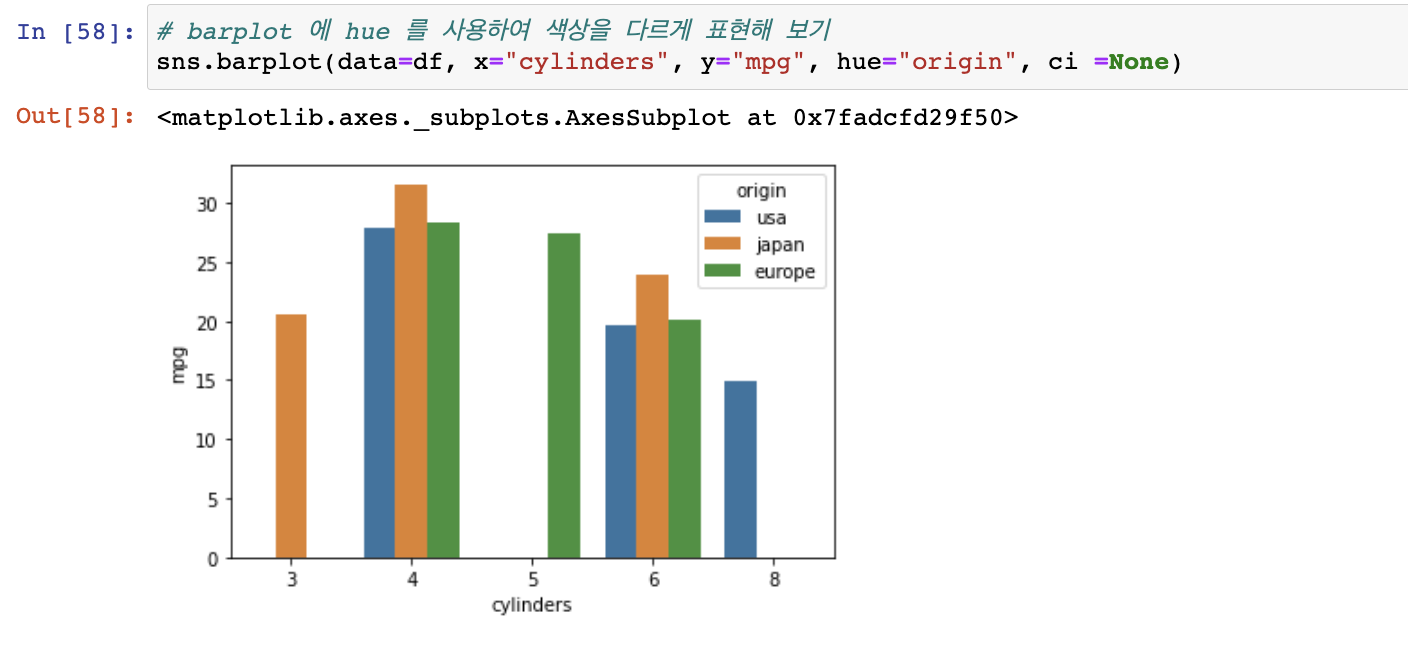
pd.pivot_table(data=df, index="origin", columns = "cylinders", values = "mpg")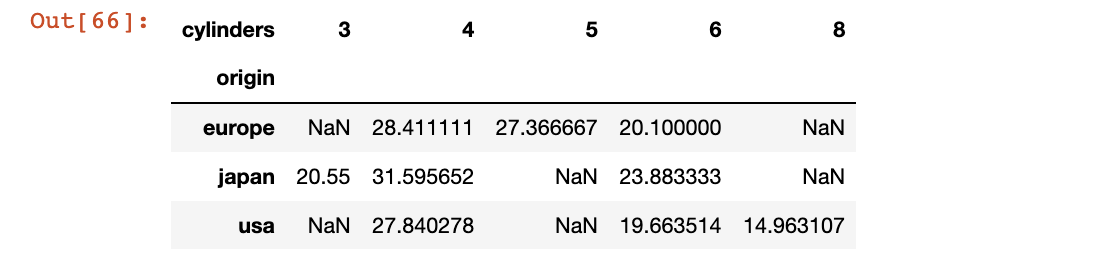
3. 그룹바이 group by *자주 사용*
df.groupby('기준컬럼명')['가져올 컬럼명'].연산()
# df.groupby('class')["fare"].count() 조건은 df[]안에!
df[df["fare"] > 50].groupby('class')["fare"].count()
df.groupby(by="deck")["deck"].count().sort_values
# 업종명으로 그룹화해서 카드이용금액이 상위 5개인 결과 가져오기
df.groupby(by="업종명")["카드이용금액"].sum().sort_values(ascending=False).iloc[:5]
그룹바이로 count, mean, sum 한 번에 구하기 (.agg 사용)
#.agg
df.groupby("deck")["fare"].agg(['count','mean','sum'])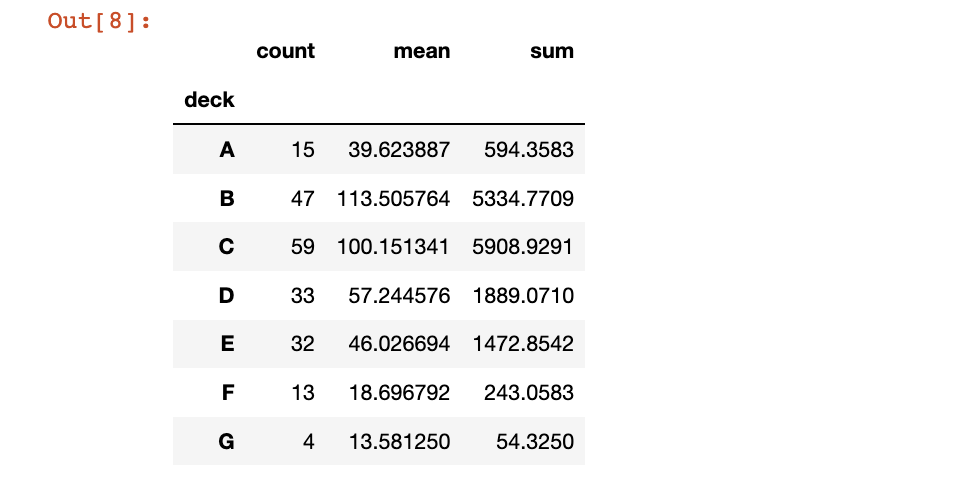
df.groupby(["class","who"]).agg({"age":"mean","fare":"mean","deck":"count"})