
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
기술통계
df.describe()
df.describe(include="object")
결측치
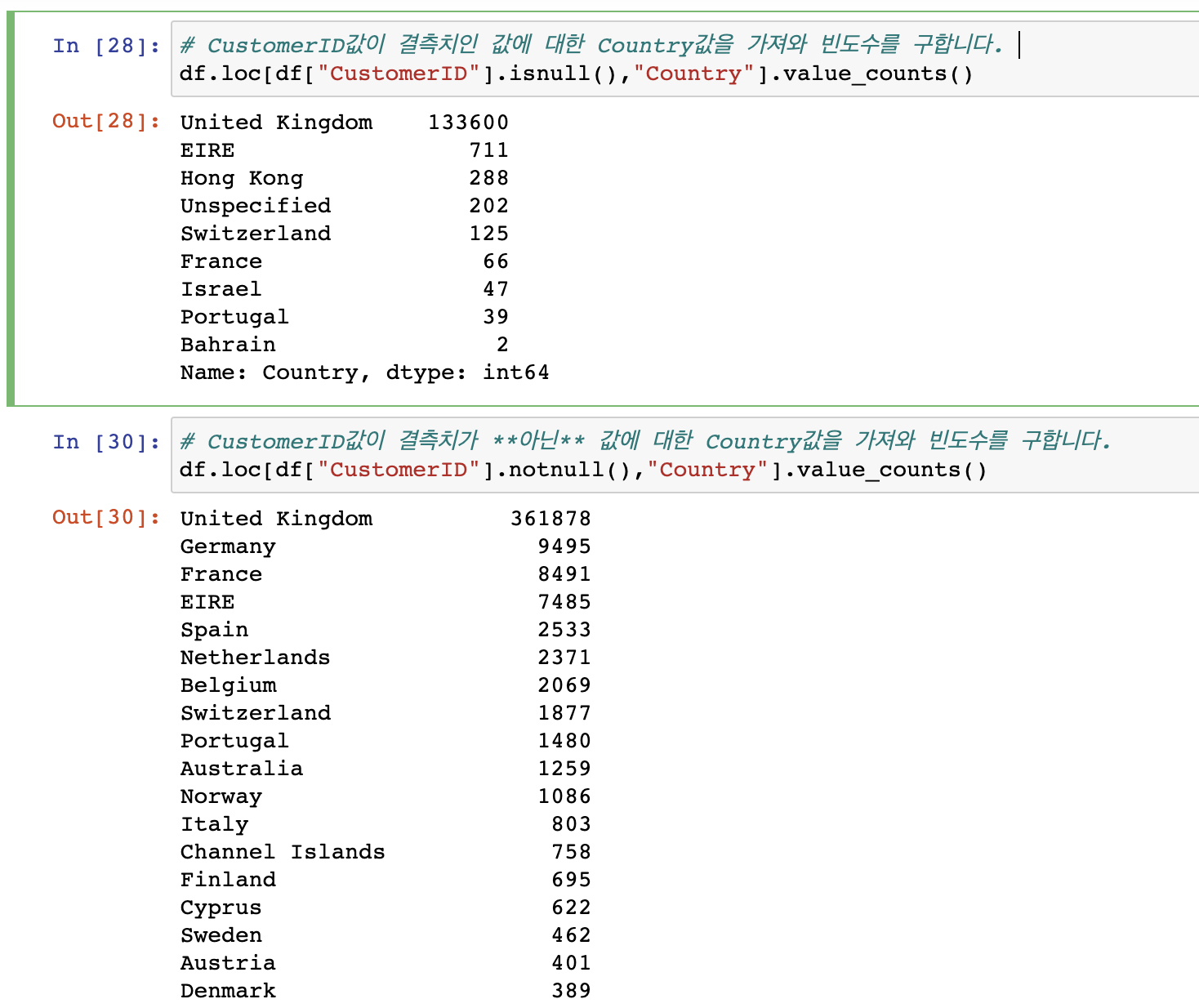
# 결측치 합계를 구합니다.
df.isnull().sum()
# 결측치 비율을 구합니다.
df.isnull().mean() * 100
# 결측치를 시각화 합니다.
plt.figure(figsize=(12, 4))
sns.heatmap(df.isnull())
히스토그램으로 전체 수치변수 시각화
df.hist(figsize=(12,5))
매출액 상위 국가
# 국가별 매출액의 평균과 합계를 구합니다.
# TotalPrice를 통해 매출액 상위 10개만 가져옵니다.
df.groupby("Country")["TotalPrice"].agg(["mean", "sum"]).nlargest(10, "sum").style.format("{:,.0f}")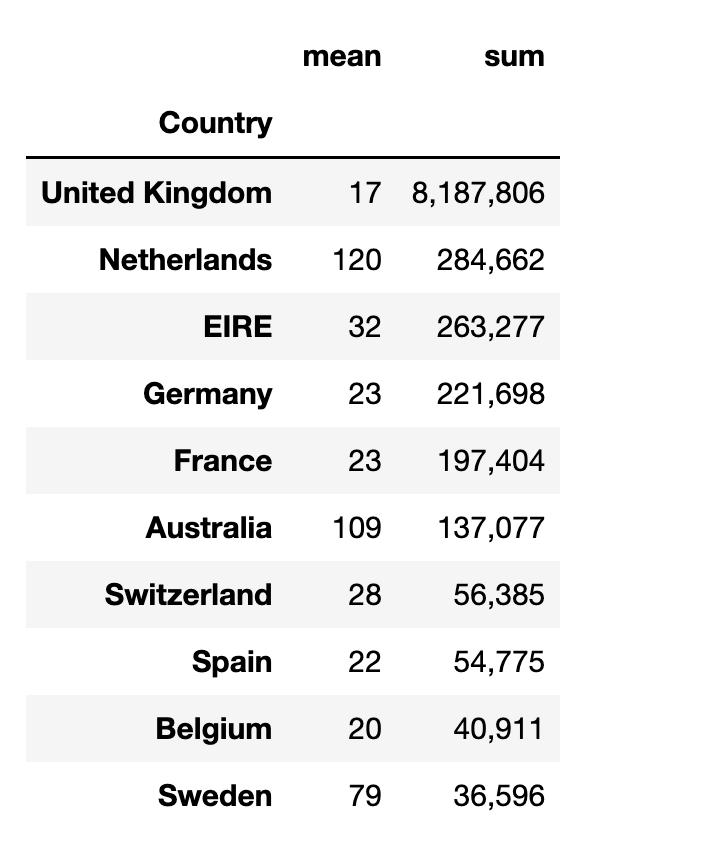
# 상품 판매 빈도, 판매 총 수량, 총 매출액
# 판매 빈도가 높은 상품 상위 10개
stock_sale = df.groupby(["StockCode"]).agg({"InvoiceNo": "count",
"Quantity": "sum",
"TotalPrice": "sum"
}).nlargest(10, "InvoiceNo")
stock_sale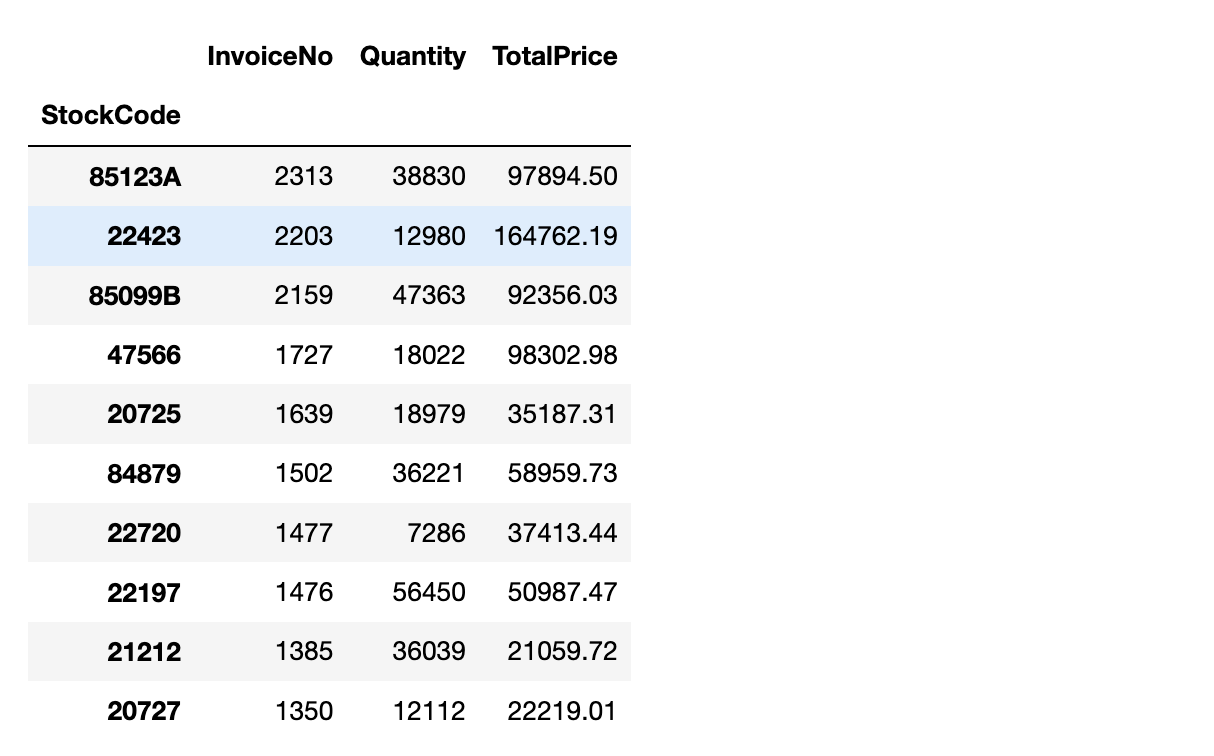
# 판매 상위 데이터의 Description 구하기
# loc[조건, 열], 중복 데이터 제거
stock_desc = df.loc[df["StockCode"].isin(stock_sale.index),
["StockCode", "Description"]].drop_duplicates("StockCode").set_index("StockCode")
stock_desc.loc[stock_sale.index]
실제 비즈니스에서 취소 주문을 다루는 방식
- 주문 취소라고 레코드를 지우면 안된다.

.unstack
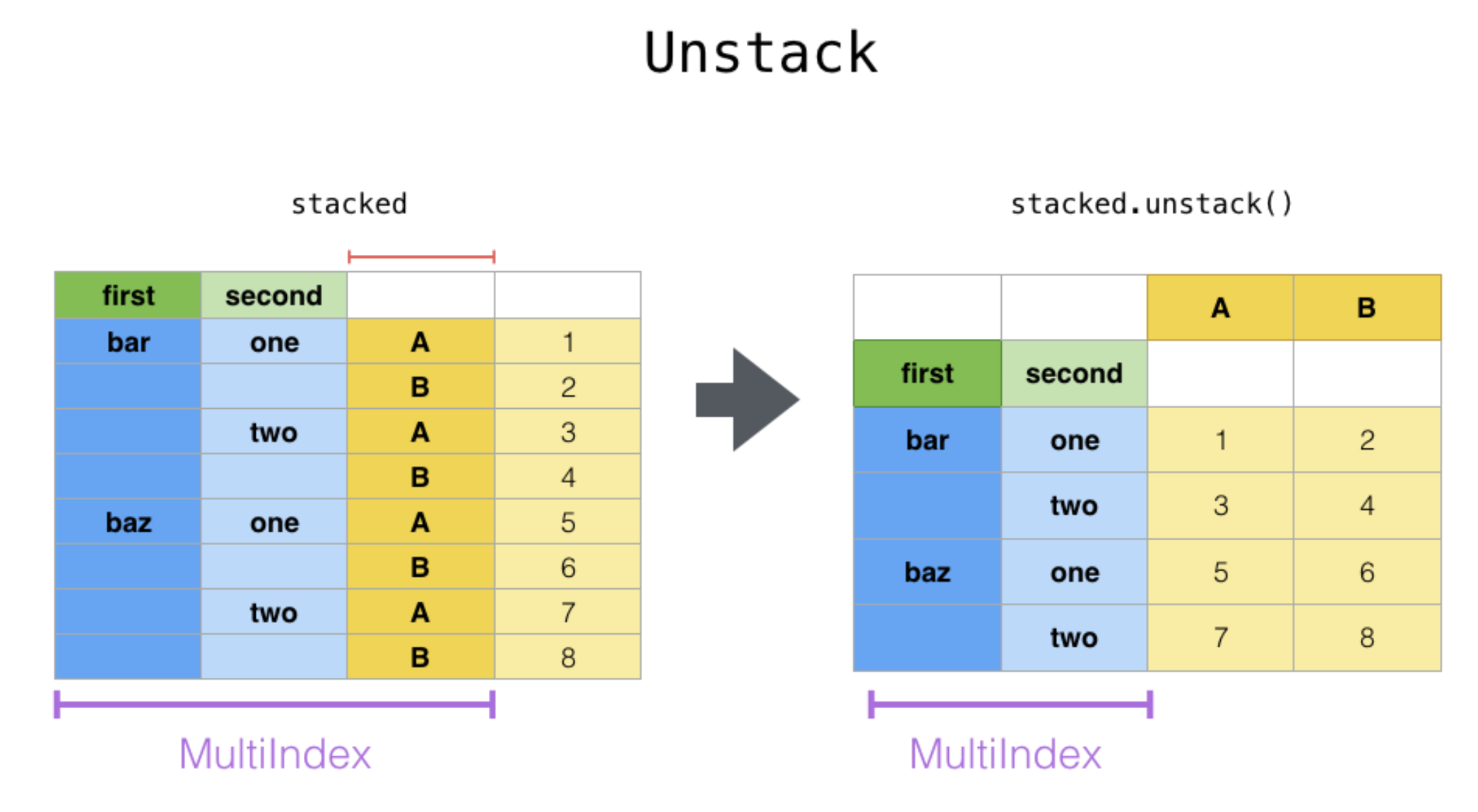
# 고객별 구매취소 비율 상위 CustomerID 10개
df.groupby("CustomerID")["Cancel"].value_counts().unstack().nlargest(10, False)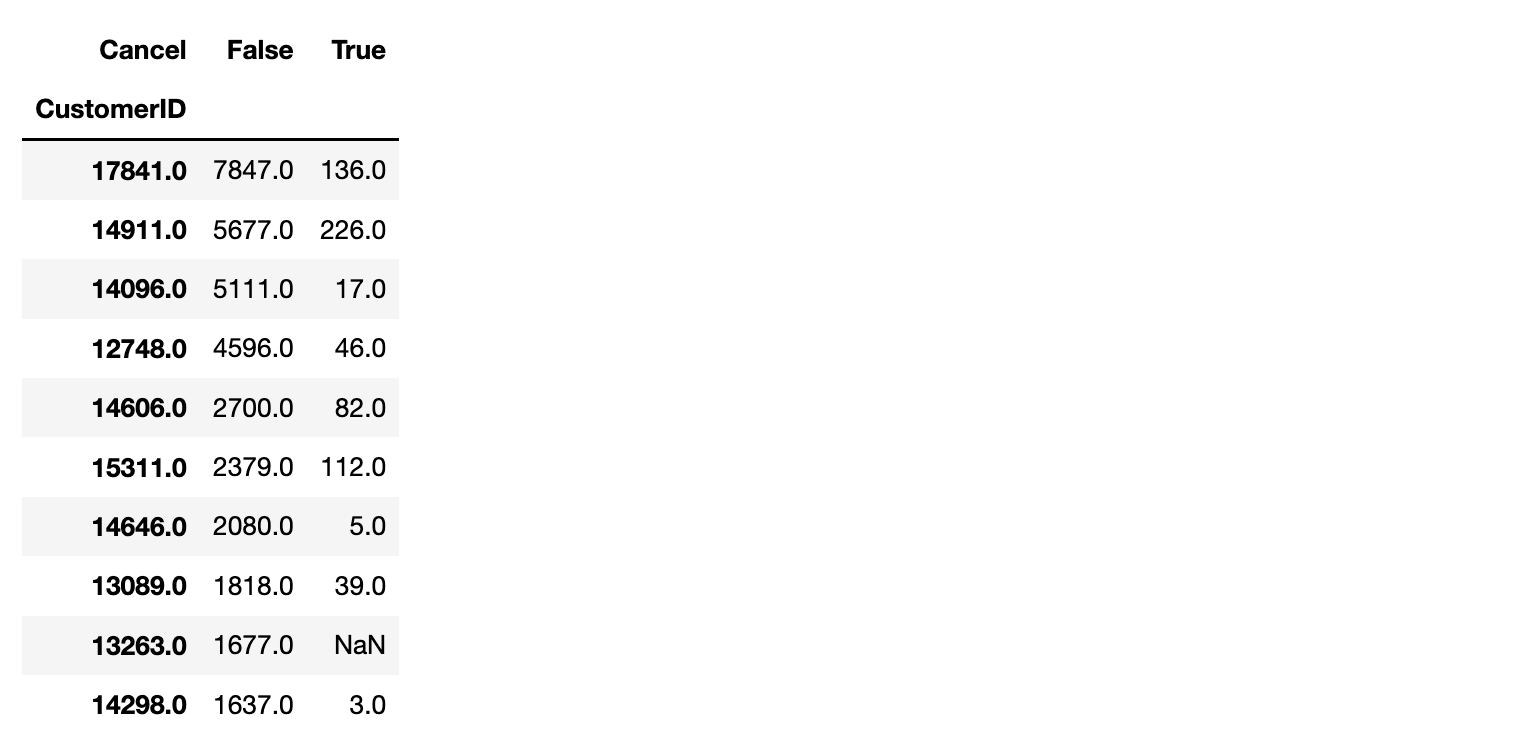
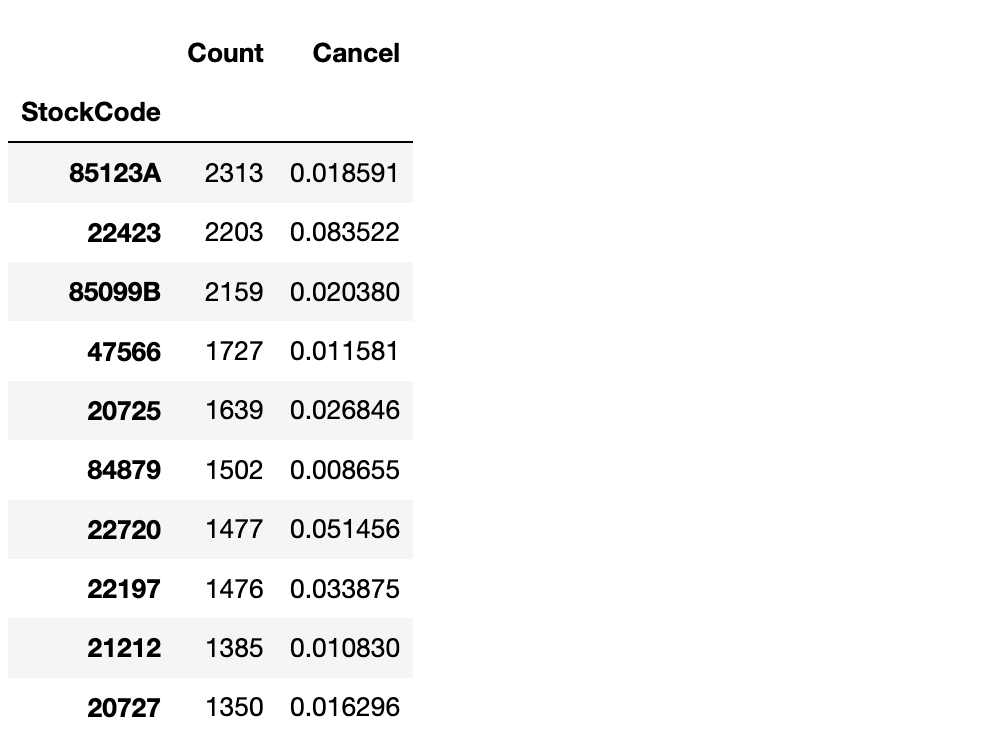
cancel_stock = df.groupby(["StockCode"]).agg({"InvoiceNo":"count", "Cancel": "mean"})
cancel_stock.columns = ["Count","Cancel"]
cancel_stock.nlargest(10, "Count")
- agg({"컬럼명":"확인할 계산", "컬럼명":"확인할 계산",})
- 컬럼명 변경 .columns = [" ", " "]
- .nlargest(숫자,"컬럼명")
데이터타입 날짜로 변환, 날짜 파생변수 만들기
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])# year, month, day, dayofweek 를 InvoiceDate에서 추출하여 파생변수로 생성합니다.
df["InvoiceYear"] = df["InvoiceDate"].dt.year
df["InvoiceMonth"] = df["InvoiceDate"].dt.month
df["InvoiceDay"] = df["InvoiceDate"].dt.day
df["InvoiceDow"] = df["InvoiceDate"].dt.dayofweek# InvoiceDate 에서 앞에서 7개문자만 가져오면([:7]) 연, 월만 따로 생성
# str으로 타입 변환 후 슬라이싱 사용
df["InvoiceYM"] = df["InvoiceDate"].astype(str).str[:7]
df["InvoiceYM"]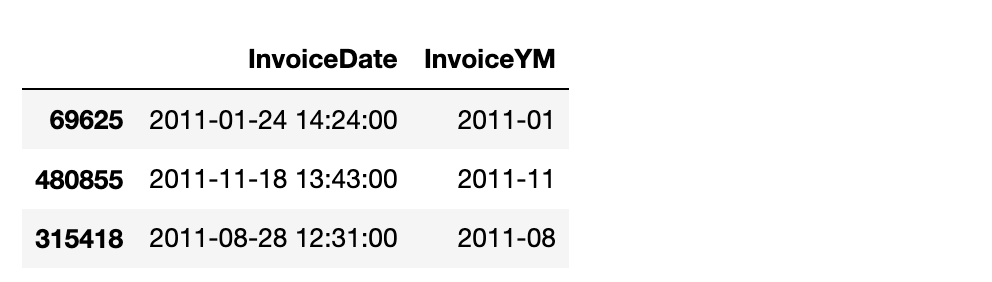
# InvoiceDate 에서 time, hour 에 대한 파생변수도 생성합니다.
df["InvoiceTime"] = df["InvoiceDate"].dt.time
df["InvoiceHour"] = df["InvoiceDate"].dt.hour날짜 만든 후에 히스토그램
# hist 로 전체 수치 변수의 히스토그램을 시각화
df.hist(bins=50, figsize=(12,10))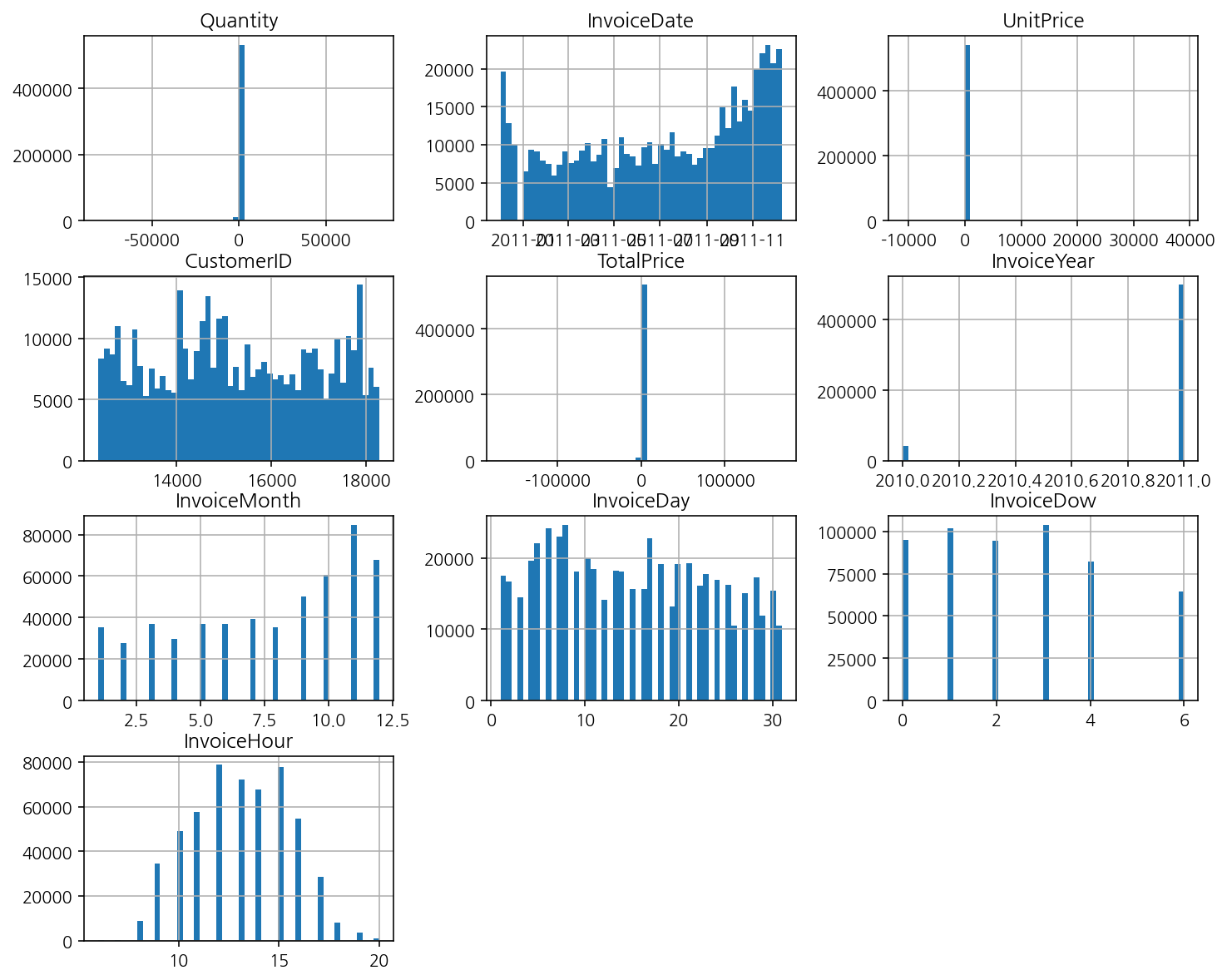
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
기술통계
df.describe()
df.describe(include="object")
결측치
# 결측치 합계를 구합니다.
df.isnull().sum()
# 결측치 비율을 구합니다.
df.isnull().mean() * 100
# 결측치를 시각화 합니다.
plt.figure(figsize=(12, 4))
sns.heatmap(df.isnull())
히스토그램으로 전체 수치변수 시각화
df.hist(figsize=(12,5))
매출액 상위 국가
# 국가별 매출액의 평균과 합계를 구합니다.
# TotalPrice를 통해 매출액 상위 10개만 가져옵니다.
df.groupby("Country")["TotalPrice"].agg(["mean", "sum"]).nlargest(10, "sum").style.format("{:,.0f}")# 상품 판매 빈도, 판매 총 수량, 총 매출액
# 판매 빈도가 높은 상품 상위 10개
stock_sale = df.groupby(["StockCode"]).agg({"InvoiceNo": "count",
"Quantity": "sum",
"TotalPrice": "sum"
}).nlargest(10, "InvoiceNo")
stock_sale# 판매 상위 데이터의 Description 구하기
# loc[조건, 열], 중복 데이터 제거
stock_desc = df.loc[df["StockCode"].isin(stock_sale.index),
["StockCode", "Description"]].drop_duplicates("StockCode").set_index("StockCode")
stock_desc.loc[stock_sale.index]실제 비즈니스에서 취소 주문을 다루는 방식
- 주문 취소라고 레코드를 지우면 안된다.
.unstack
# 고객별 구매취소 비율 상위 CustomerID 10개
df.groupby("CustomerID")["Cancel"].value_counts().unstack().nlargest(10, False)cancel_stock = df.groupby(["StockCode"]).agg({"InvoiceNo":"count", "Cancel": "mean"})
cancel_stock.columns = ["Count","Cancel"]
cancel_stock.nlargest(10, "Count")
- agg({"컬럼명":"확인할 계산", "컬럼명":"확인할 계산",})
- 컬럼명 변경 .columns = [" ", " "]
- .nlargest(숫자,"컬럼명")
데이터타입 날짜로 변환, 날짜 파생변수 만들기
df["InvoiceDate"] = pd.to_datetime(df["InvoiceDate"])# year, month, day, dayofweek 를 InvoiceDate에서 추출하여 파생변수로 생성합니다.
df["InvoiceYear"] = df["InvoiceDate"].dt.year
df["InvoiceMonth"] = df["InvoiceDate"].dt.month
df["InvoiceDay"] = df["InvoiceDate"].dt.day
df["InvoiceDow"] = df["InvoiceDate"].dt.dayofweek# InvoiceDate 에서 앞에서 7개문자만 가져오면([:7]) 연, 월만 따로 생성
# str으로 타입 변환 후 슬라이싱 사용
df["InvoiceYM"] = df["InvoiceDate"].astype(str).str[:7]
df["InvoiceYM"]# InvoiceDate 에서 time, hour 에 대한 파생변수도 생성합니다.
df["InvoiceTime"] = df["InvoiceDate"].dt.time
df["InvoiceHour"] = df["InvoiceDate"].dt.hour날짜 만든 후에 히스토그램
# hist 로 전체 수치 변수의 히스토그램을 시각화
df.hist(bins=50, figsize=(12,10))