
28일차 멋사 AI스쿨 main lecture by 박조은 강사님
오늘의 회고
사실(Fact): 머신러닝 결정트리학습법, 당뇨병 예측 실습
느낌(Feeling): 어제보다는 지도학습, 비지도학습에 대해 이해가 되는데, 지니불순도나 엔트로피 같은 용어가 단번에 이해하기 어려웠다
교훈(Finding): 오늘 과제를 해결하면서 복습하고, 유튜브 영상을 많이 참고해야겠다.
+)
그리고 TIL 쓰는 스타일을 바꿔보려고 하는데 좀 어렵다
자세한 내용보단 뭘배웠는지 위주로 적고, 자세한 내용은 스스로 실습을 하면서 정리하면 좋을 거같다.
머신러닝을 통한 현실세계의 문제 해결
1. 지도학습 VS 비지도학습
(정답 == label == target) 있으면 지도학습, 없으면 비지도 학습
2. 지도 학습이라면, 그 중에서도 분류로 할수있는 일, 회귀로 할수있는 일 생각해보기
3. 어떤 알고리즘이 좋을지 선택하기
ex) 지도 학습 알고리즘
- 분류문제 - 로지스틱 회귀, 나이브 베이즈 분류
- 회귀문제 - 선형 회귀, 정규화
- 둘 다 - 서포트 벡터 머신, 랜덤 포레스트, 신경망 ...
분류
- 이미지 분류
- 질문 분류 (민원 처리부서 분류)
- 스팸메일 분류
- 자연어 텍스트를 분류
- 물류 - 배송지 분류
- 상품 카테고리, 진열 분류
- 암 진단하기 (사진을 통한 질병 진단)
- 웹사이트의 언어 확인
- 게임회사 등 → 이상치탐지, 이상유저 분류 (욕설, 핵프로그램, 트롤)
- 광고 → 가짜 유저 (abuser) 탐지
https://datascienceschool.net/03 machine learning/09.01 분류용 예제 데이터.html
회귀
- 주식, 주가 예측
- 주택 가격 예측
- 기상 - 기온, 강수량 예측
- 제품 수율 예측 (반도체 등)
- 농산물 생산량, 수요량, 수확량 예측
- 광고의 클릭률, 전환률 예측
- 관객수 예측
- 투표율 / 당선 예측
- 기간별 매출액
- 서버의 트래픽양 예측
GitHub - amueller/odscon-2015: Slides and material for open data science
Slides and material for open data science. Contribute to amueller/odscon-2015 development by creating an account on GitHub.
github.com
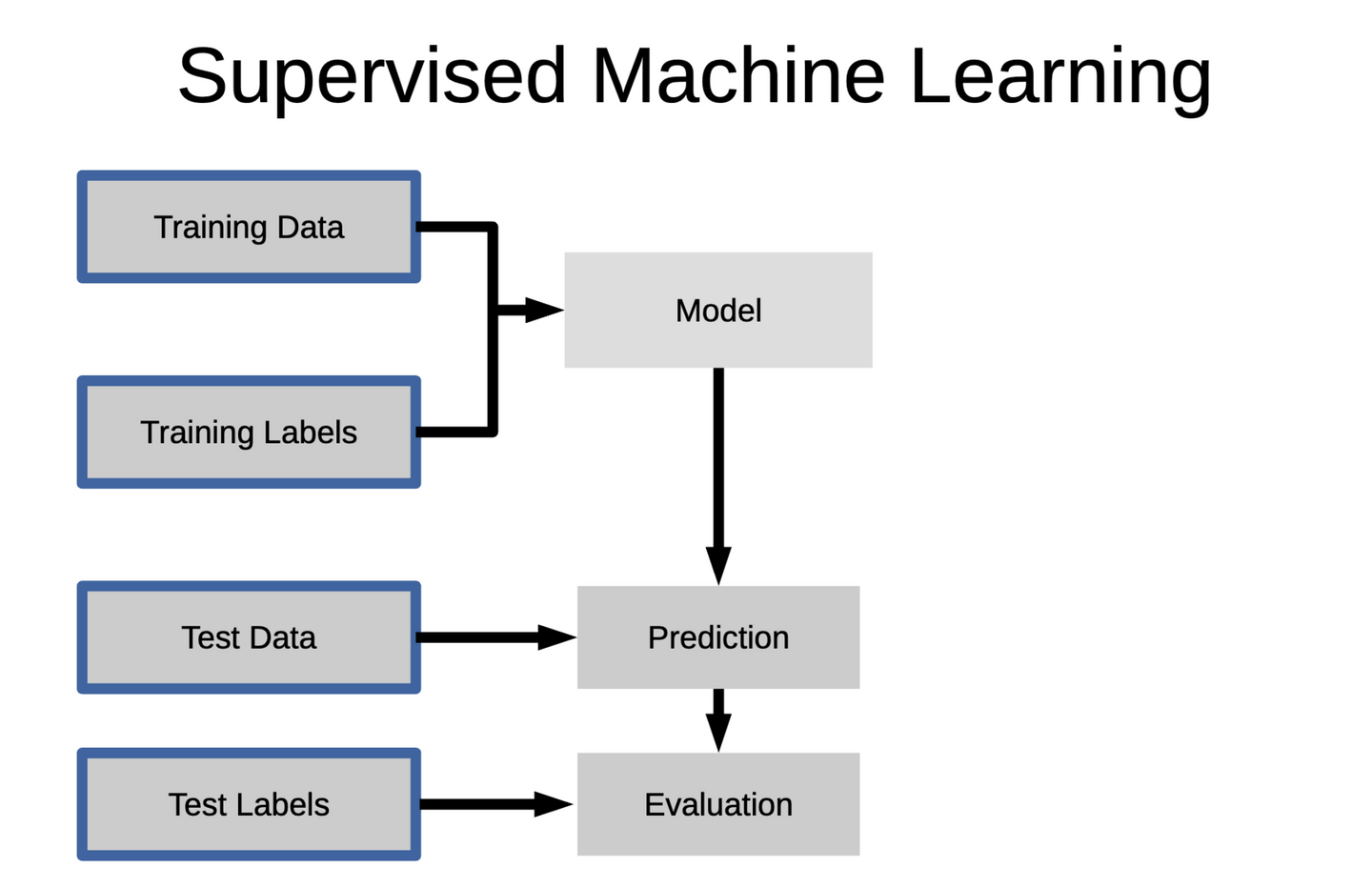
오늘 수업에서 가장 중요한 도식
model >> Prediction >> Evaluation
기출문제로 Training하고, 실제 시험에서 Test한다고 이해하면 쉽다
학습할땐 Fit / 실제 시험, 예측은 Predict
feature_names : 학습, 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아준다.
딥러닝은 머신러닝의 종류 중 하나로 도식에서 Model에 신경망 학습이 들어간다고 생각하면 된다.
결정 트리 학습법 Decision Tree
첫번째로 배운 알고리즘. 스무고개 게임과 비슷하다고 생각하면 이해하기 쉽다.
트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라고 한다.
결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 것은 회귀 트리라 한다
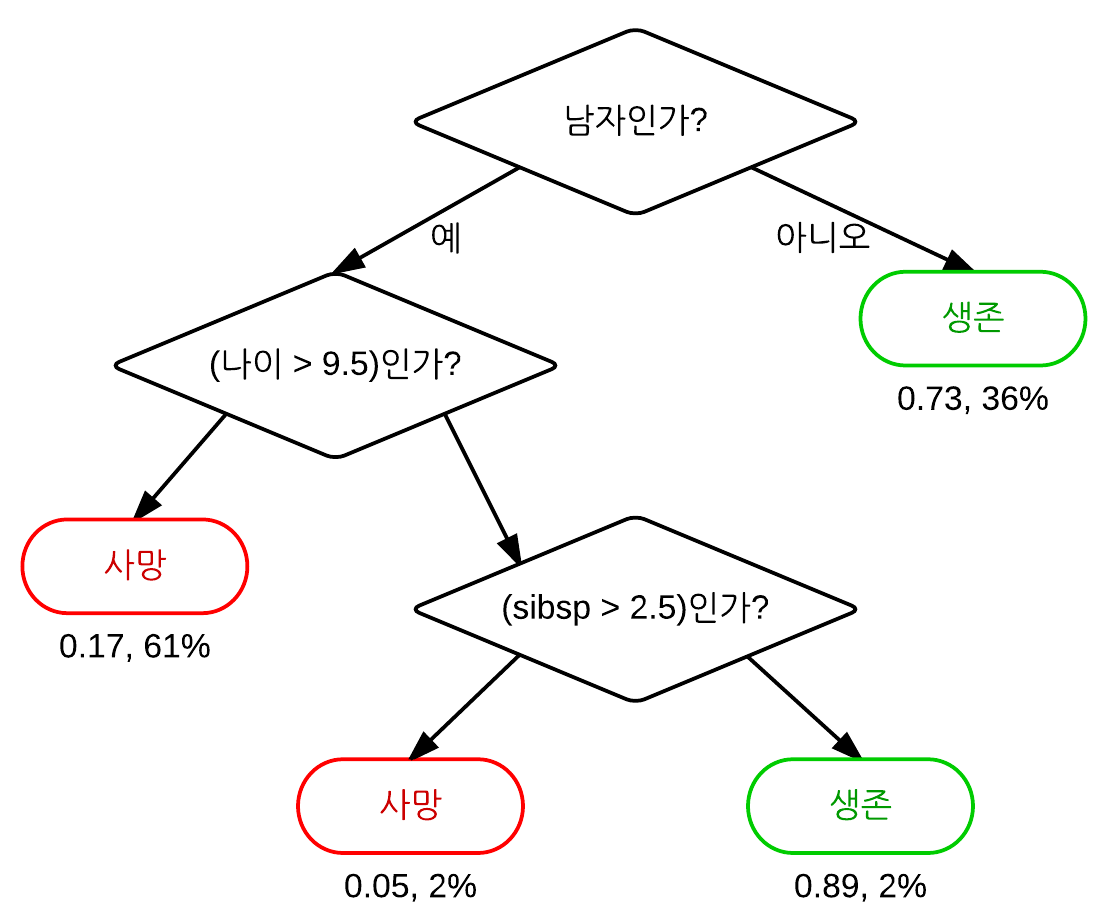
CART 알고리즘 (분류 및 회귀 트리)
- 랜덤 포레스트
- 부스트트리
- 회전 포레스트
(https://ko.wikipedia.org/wiki/%EA%B2%B0%EC%A0%95_%ED%8A%B8%EB%A6%AC_%ED%95%99%EC%8A%B5%EB%B2%95)
결정트리의 장점
- 결과를 해석하고 이해하기 쉽다.
- 자료를 전처리 할 필요가 거의 없다.
- 수치 자료와 범주 자료 모두에 적용할 수 있다.
- 화이트박스 모델을 사용한다. 모델에서 주어진 상황이 관측 가능하다면 불 논리를 이용하여 조건에 대해 쉽게 설명할 수 있다. (결과에 대한 설명을 이해하기 어렵기 때문에 인공신경망은 대표적인 블랙 박스 모델이다.)
- 대규모의 데이터 셋에서도 잘 동작한다.
당뇨병 예측 실습
전체 데이터 중 80%는 학습, 나머지는 예측으로 나누어서 사용
처음에 변수에 할당을 잘해야한다. 안그러면 예측 정확도가 100%가 나오는 문제(?!) 발생
오버피팅 == 과대적합 == 과적합
학습하지 않아도 되는 부분까지 학습해서 쓸데없는 부분까지 학습해서 오히려 오답
언더피팅 == 과소적합
'학습을 적게해서 점수가 낮게 나오는 것
지니계수, 지니불순도, 엔트로피 -> 추가 공부 필요
참고링크: https://hleecaster.com/ml-decision-tree-concept/
p가 0.5가 최악의 경우이다. 치 짜장면이 좋아 짬뽕이 좋아 물었을떄 ‘아무거나’라고 말한 상태 같은 것이다
트리를 그리다가 gini=0이되면 트리가 뻗어나가는 것을 멈추게된다
사이킷런 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42, max_depth=6, min_samples_leaf=6).fit 학습하기 / .predict 예측하기
# 학습
model.fit(X_train, y_train)
# nan값이 있으면 학습이 안된다.
# 예측
y_predict = model.predict(X_test)예측 정확도 계산하기 3가지 방법
# 직접 계산하기
(y_test == y_predict).mean()
# 미리 구현된 알고리즘 가져오기
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
# score 활용
model.score(X_test, y_test)현실세계에서는 당뇨 진단에 인슐린이 중요도가 크다고 알고있는데, 분석결과 글루코스가 더 높았다.
그렇다면? EDA를 통해 인슐린 중요도가 왜 낮게 나왔는지 분석해본다.
데이터를 뜯어보니 인슐린 데이터가 0인 경우가 많았다 (결측치로 변경 후 확인한 비율

데이터가 0인 값을 결측치로 취급 후, 결측치를 평균값으로 채우는 전처리를 실습하였다.
# 0인 데이터를 결측값으로 바꾸기
df["Insulin_nan"] = df["Insulin"].replace(0,np.nan)
# 결측치 채우기
# 중요한 데이터인데 누락이 될 수 있고, 편향될 가능성이 있어서 평균값으로 채움
df["Insulin_fill"] = df["Insulin_nan"]
df.loc[(df['Outcome']==0)&(df["Insulin_nan"].isnull()), 'Insulin_fill'] = Insulin_mean.loc[0]
df.loc[(df['Outcome']==1)&(df["Insulin_nan"].isnull()), 'Insulin_fill'] = Insulin_mean.loc[1]
df["Insulin_fill"].isnull().sum()데이터 전처리 후 Insulin -> Insulin_fill 중요도 차이!!
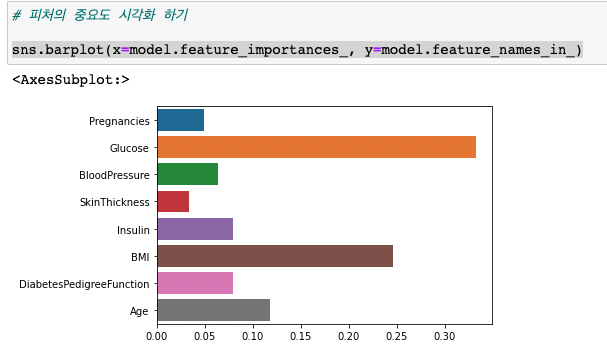
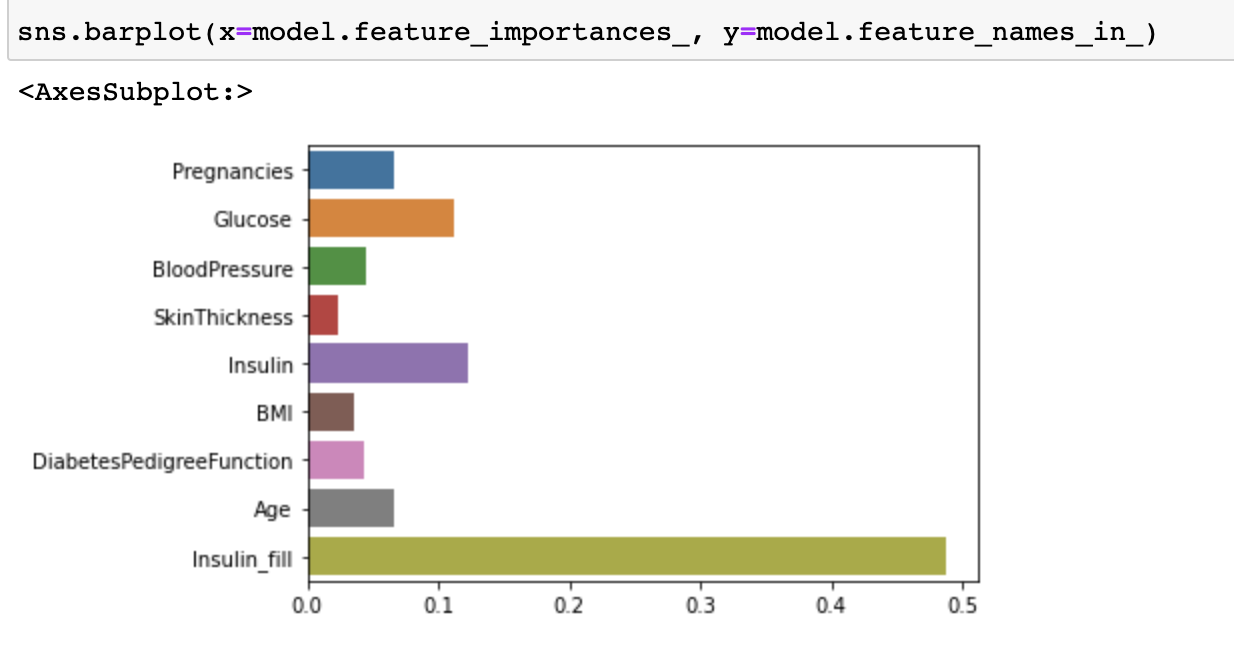
정확도(Accuracy) 도 상승! 0.71 -> 0.88
28일차 멋사 AI스쿨 main lecture by 박조은 강사님
오늘의 회고
사실(Fact): 머신러닝 결정트리학습법, 당뇨병 예측 실습
느낌(Feeling): 어제보다는 지도학습, 비지도학습에 대해 이해가 되는데, 지니불순도나 엔트로피 같은 용어가 단번에 이해하기 어려웠다
교훈(Finding): 오늘 과제를 해결하면서 복습하고, 유튜브 영상을 많이 참고해야겠다.
+)
그리고 TIL 쓰는 스타일을 바꿔보려고 하는데 좀 어렵다
자세한 내용보단 뭘배웠는지 위주로 적고, 자세한 내용은 스스로 실습을 하면서 정리하면 좋을 거같다.
머신러닝을 통한 현실세계의 문제 해결
1. 지도학습 VS 비지도학습
(정답 == label == target) 있으면 지도학습, 없으면 비지도 학습
2. 지도 학습이라면, 그 중에서도 분류로 할수있는 일, 회귀로 할수있는 일 생각해보기
3. 어떤 알고리즘이 좋을지 선택하기
ex) 지도 학습 알고리즘
- 분류문제 - 로지스틱 회귀, 나이브 베이즈 분류
- 회귀문제 - 선형 회귀, 정규화
- 둘 다 - 서포트 벡터 머신, 랜덤 포레스트, 신경망 ...
분류
- 이미지 분류
- 질문 분류 (민원 처리부서 분류)
- 스팸메일 분류
- 자연어 텍스트를 분류
- 물류 - 배송지 분류
- 상품 카테고리, 진열 분류
- 암 진단하기 (사진을 통한 질병 진단)
- 웹사이트의 언어 확인
- 게임회사 등 → 이상치탐지, 이상유저 분류 (욕설, 핵프로그램, 트롤)
- 광고 → 가짜 유저 (abuser) 탐지
https://datascienceschool.net/03 machine learning/09.01 분류용 예제 데이터.html
회귀
- 주식, 주가 예측
- 주택 가격 예측
- 기상 - 기온, 강수량 예측
- 제품 수율 예측 (반도체 등)
- 농산물 생산량, 수요량, 수확량 예측
- 광고의 클릭률, 전환률 예측
- 관객수 예측
- 투표율 / 당선 예측
- 기간별 매출액
- 서버의 트래픽양 예측
GitHub - amueller/odscon-2015: Slides and material for open data science
Slides and material for open data science. Contribute to amueller/odscon-2015 development by creating an account on GitHub.
github.com
오늘 수업에서 가장 중요한 도식
model >> Prediction >> Evaluation
기출문제로 Training하고, 실제 시험에서 Test한다고 이해하면 쉽다
학습할땐 Fit / 실제 시험, 예측은 Predict
feature_names : 학습, 예측에 사용할 컬럼을 리스트 형태로 만들어서 변수에 담아준다.
딥러닝은 머신러닝의 종류 중 하나로 도식에서 Model에 신경망 학습이 들어간다고 생각하면 된다.
결정 트리 학습법 Decision Tree
첫번째로 배운 알고리즘. 스무고개 게임과 비슷하다고 생각하면 이해하기 쉽다.
트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라고 한다.
결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 것은 회귀 트리라 한다
CART 알고리즘 (분류 및 회귀 트리)
- 랜덤 포레스트
- 부스트트리
- 회전 포레스트
(https://ko.wikipedia.org/wiki/%EA%B2%B0%EC%A0%95_%ED%8A%B8%EB%A6%AC_%ED%95%99%EC%8A%B5%EB%B2%95)
결정트리의 장점
- 결과를 해석하고 이해하기 쉽다.
- 자료를 전처리 할 필요가 거의 없다.
- 수치 자료와 범주 자료 모두에 적용할 수 있다.
- 화이트박스 모델을 사용한다. 모델에서 주어진 상황이 관측 가능하다면 불 논리를 이용하여 조건에 대해 쉽게 설명할 수 있다. (결과에 대한 설명을 이해하기 어렵기 때문에 인공신경망은 대표적인 블랙 박스 모델이다.)
- 대규모의 데이터 셋에서도 잘 동작한다.
당뇨병 예측 실습
전체 데이터 중 80%는 학습, 나머지는 예측으로 나누어서 사용
처음에 변수에 할당을 잘해야한다. 안그러면 예측 정확도가 100%가 나오는 문제(?!) 발생
오버피팅 == 과대적합 == 과적합
학습하지 않아도 되는 부분까지 학습해서 쓸데없는 부분까지 학습해서 오히려 오답
언더피팅 == 과소적합
'학습을 적게해서 점수가 낮게 나오는 것
지니계수, 지니불순도, 엔트로피 -> 추가 공부 필요
참고링크: https://hleecaster.com/ml-decision-tree-concept/
p가 0.5가 최악의 경우이다. 치 짜장면이 좋아 짬뽕이 좋아 물었을떄 ‘아무거나’라고 말한 상태 같은 것이다
트리를 그리다가 gini=0이되면 트리가 뻗어나가는 것을 멈추게된다
사이킷런 모델 불러오기
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(random_state=42, max_depth=6, min_samples_leaf=6).fit 학습하기 / .predict 예측하기
# 학습
model.fit(X_train, y_train)
# nan값이 있으면 학습이 안된다.
# 예측
y_predict = model.predict(X_test)예측 정확도 계산하기 3가지 방법
# 직접 계산하기
(y_test == y_predict).mean()
# 미리 구현된 알고리즘 가져오기
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
# score 활용
model.score(X_test, y_test)현실세계에서는 당뇨 진단에 인슐린이 중요도가 크다고 알고있는데, 분석결과 글루코스가 더 높았다.
그렇다면? EDA를 통해 인슐린 중요도가 왜 낮게 나왔는지 분석해본다.
데이터를 뜯어보니 인슐린 데이터가 0인 경우가 많았다 (결측치로 변경 후 확인한 비율
데이터가 0인 값을 결측치로 취급 후, 결측치를 평균값으로 채우는 전처리를 실습하였다.
# 0인 데이터를 결측값으로 바꾸기
df["Insulin_nan"] = df["Insulin"].replace(0,np.nan)
# 결측치 채우기
# 중요한 데이터인데 누락이 될 수 있고, 편향될 가능성이 있어서 평균값으로 채움
df["Insulin_fill"] = df["Insulin_nan"]
df.loc[(df['Outcome']==0)&(df["Insulin_nan"].isnull()), 'Insulin_fill'] = Insulin_mean.loc[0]
df.loc[(df['Outcome']==1)&(df["Insulin_nan"].isnull()), 'Insulin_fill'] = Insulin_mean.loc[1]
df["Insulin_fill"].isnull().sum()데이터 전처리 후 Insulin -> Insulin_fill 중요도 차이!!
정확도(Accuracy) 도 상승! 0.71 -> 0.88