자연어 처리 모델 참고 영상
https://www.youtube.com/watch?v=fTQRplbzI1o&t=89s
GPT
- 데이터 플로우 단방향
- 두 단계로 나누어 학습 (비지도 학습 pre-training, fine tuning)
- 시퀀스 투 시퀀스 모델링에서의 디코더
- Pre-training 단어들의 관계를 최대화 시키는 과정
뒤에 나올 단어의 확률을 최대화시킴 - Fine-tuning: 학습 과정. task에 맞춰서 파라미터를 튜닝함.
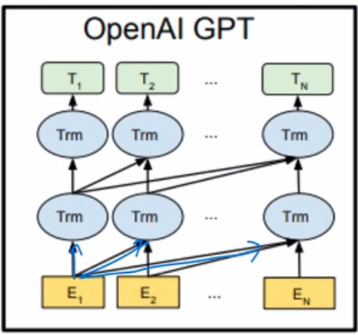
GPT의 구조
left to right 문장이 흘러가는 방향대로 attention
GPT2, GPT3

BERT
- Bidirectional Encoder Representation from Transformers
- 단방향 학습하는 GPT와 다르게 데이터 플로우 양방향
- GPT와 유사한 Pre-trainingrhk fine tuning단계로 학습
MASKED LM
- 전체 시퀀스의 15%에 마스크를 씌움
- 마스크의 80%는 [mask]라는 토큰을 갖고, 10%는 무작위토큰, 나머지 10%는 원래 단어 그대로 활용
- 이렇게 함으로써 시퀀스 전체를 학습할 수 있다.

(gpt는 100% mask, bert는 20% 무작위 또는 원래 단어로 문장 전체 활용)
NEXT SENTENCE PREDICTION

CLS NSP
PRE-TRAINING, FINE TUNING
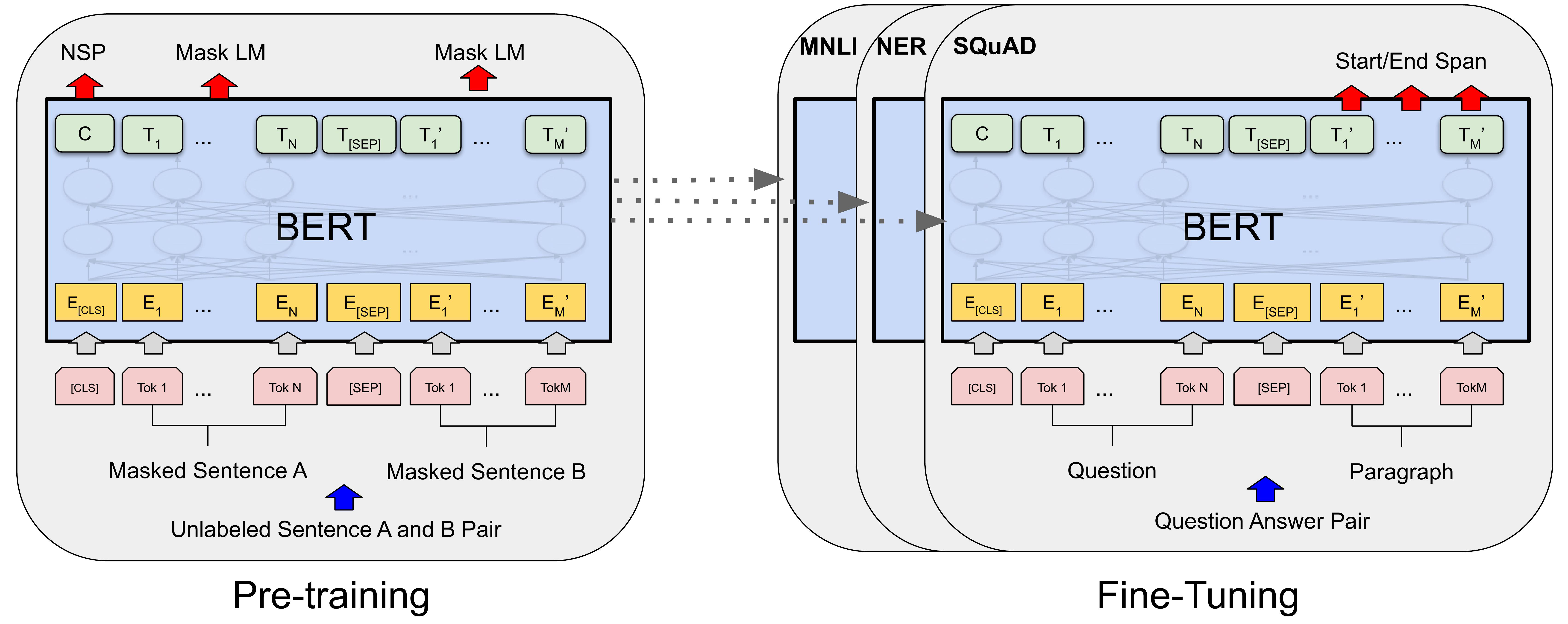
https://production-media.paperswithcode.com/methods/new_BERT_Overall.jpg
BERT는 GPT2와 다르게 task specific 하게 fine tuning을 해주어야 함.
question -> source text
paragraph -> target language
{kind=link}
4가지 시나리오에 맞춰 bert를 fine-tuning
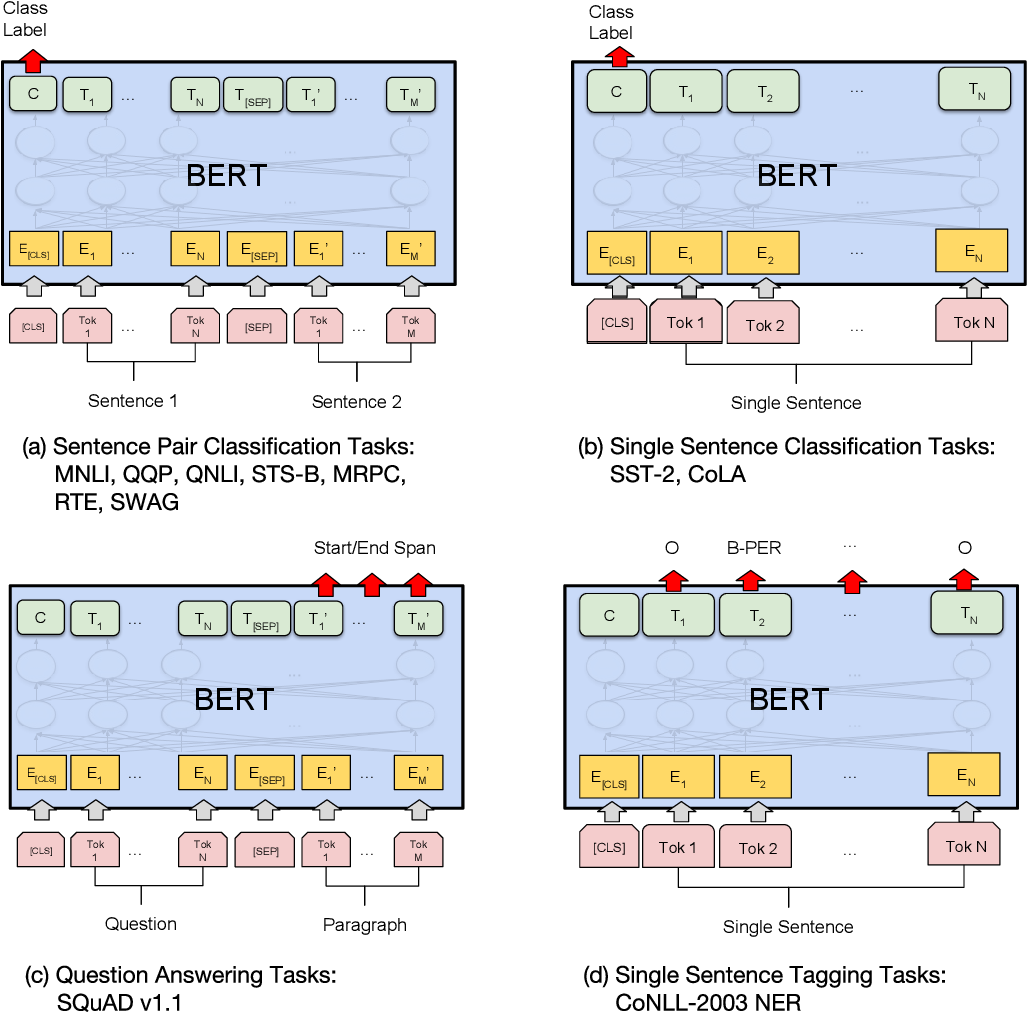
bert의 입력토큰

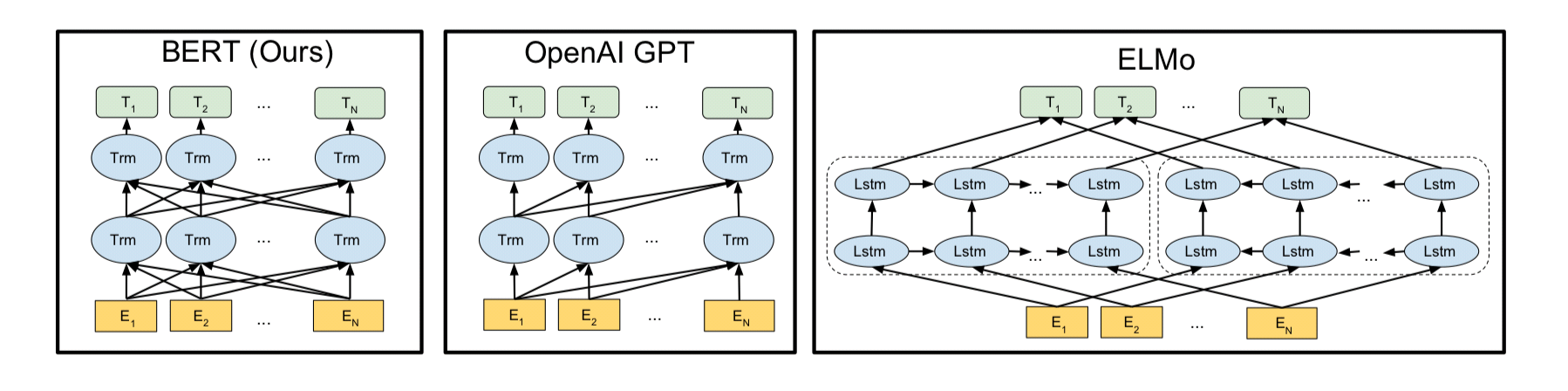
출처: https://tmaxai.github.io/post/BERT/
GAN
출처 https://www.youtube.com/watch?v=dI1AiK_uN9Q
- generative Adversarial Network
- 생성적 적대 신경망, 2014년에 개발됨
concept -> 서로 경쟁적으로 속이기 위해 학습함
적용 사례
- style transfer (화풍 모방)
- super-resolution (고화질 변환)

(gan의 특징은 loss function의 영향을 덜 받는다)
GAN: Generative Adversarial Networks (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) - 동빈나
https://www.youtube.com/watch?v=AVvlDmhHgC4
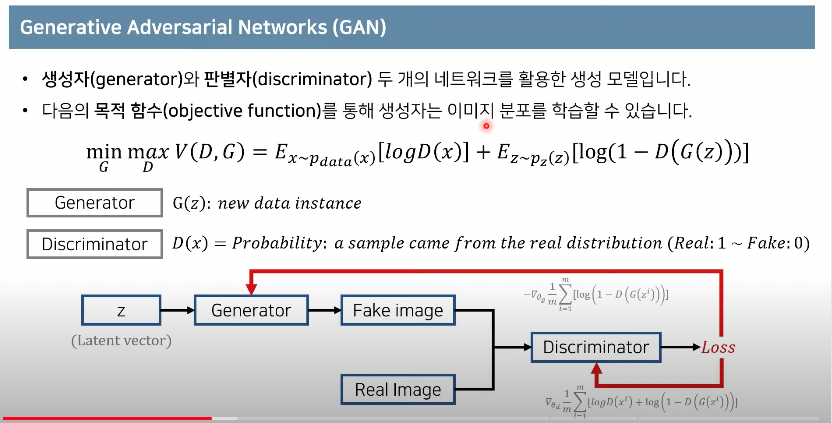
- 생성자(generator)와 판별자(discriminator) 두 개의 네트워크를 활용한 생성 모델
MNIST 실습 코드 참고
https://github.com/ndb796/Deep-Learning-Paper-Review-and-Practice/blob/master/code_practices/GAN_for_MNIST_Tutorial.ipynb
GitHub - ndb796/Deep-Learning-Paper-Review-and-Practice: 꼼꼼한 딥러닝 논문 리뷰와 코드 실습
꼼꼼한 딥러닝 논문 리뷰와 코드 실습. Contribute to ndb796/Deep-Learning-Paper-Review-and-Practice development by creating an account on GitHub.
github.com