
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
NLP 단어 벡터화하기
BOW(bag of words)
- 가장 간단하지만 효과적이라 널리쓰이는 말뭉치 방법
- 각 단어가 이 말뭉치에 몇 번 나타나는지 파악(출현 회수 카운트)
- BOW는 단어의 순서가 완전히 무시 된다는 단점이 있다.
- it's bad, not good at all.
- it's good, not bad at all.
- 위 두 문장은 의미가 전혀 반대지만 완전히 동일하게 반환된다.
- 이를 보완하기 위해 n-gram을 사용한다. (n-gram은 n개의 토큰을 사용한다.)
CountVectorizer
CountVectorizer 는 사이킷런에서 제공하는 bag of words 를 만들 수 있는 방법이다
- 문서를 토큰 리스트로 변환한다.
- 각 문서에서 토큰의 출현 빈도를 센다.
- 각 문서를 BOW 인코딩 벡터로 변환한다.
- 매개 변수
analyzer : 단어, 문자 단위의 벡터화 방법 정의
ngram_range : BOW 단위 수 (1, 3) 이라면 1개~3개까지 토큰을 묶어서 벡터화
max_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 높은 용어(말뭉치 관련 불용어)는 제외 (기본값=1.0)
max_df = 0.90 : 문서의 90% 이상에 나타나는 단어 제외
max_df = 10 : 10개 이상의 문서에 나타나는 단어 제외
min_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 낮은 용어는 제외합니다. 컷오프라고도 합니다.(기본값=1.0)
min_df = 0.01 : 문서의 1% 미만으로 나타나는 단어 제외
min_df = 10 : 문서에 10개 미만으로 나타나는 단어 제외
stop_words : 불용어 정의from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()
cvect.fit_transform(corpus)✅ fit_transform 은 학습데이터에만 사용하고 예측 데이터에는 transform 을 사용해야 한다.
➡️ 예측 데이터에도 fit_transform 을 사용하게 된다면 서로 다른 단어사전으로 행렬을 만들게 되기 때문
dtm = cvect.fit_transform(corpus)# 단어 사전 보기
vocab = cvect.get_feature_names_out()
vocab

단어사전은 {"단어": 인덱스번호}
cvect.vocabulary_
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)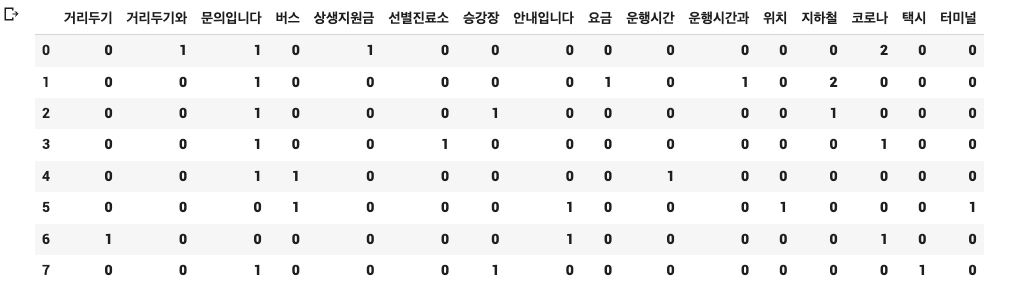
# df_dtm.sum 으로 빈도수 합계 구하기
df_dtm.sum()매개 변수 들여다 보기
N-grams
- 토큰을 몇 개 사용할 것인지를 구분, 지정한 n개의 숫자 만큼의 토큰을 묶어서 사용한다.
- 예를 들어 (1, 1) 이라면 1개의 토큰을 (2, 3)이라면 2~3개의 토큰을 사용합니다.
- 기본값 = (1, 1)
- ngram_range(min_n, max_n)
cvect = CountVectorizer(ngram_range=(1, 2))
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
df_dtm
# 모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수를 만들어 활용하기
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
return df_dtm.style.background_gradient()min_df
- 지정된 임계값보다 낮은 용어 무시
- 빈도가 매우 낮은 특이한 용어를 제거하는 데 사용
- 기본값=1, float으로 지정시 %만큼 제외
max_df
- 지정된 임계값보다 높은 용어 무시
- 너무 자주 사용되서 의미가 없는 용어 제거 (불용어 등)
- 기본값 =1
- ex) max_df = 0.89로 지정시 90% 등장하는 <불용어> 제외 가능
max_features
- 벡터라이저가 학습할 어휘의 양 제한
- corpus 중 빈도수가 높은 순으로 해당 개수만큼 추출
- 기본값 = None
Stop_words(불용어)
- 자주 등장하지만 문장 내에서 큰 의미를 갖지 않는 단어(관사, 전치사, 조사, 접속사 등)
- 도메인에 따라 불용어는 달라진다.
stop_words=["코로나", "문의입니다", "터미널", "택시"]
cvect = CountVectorizer(stop_words=stop_words)
display_transform_dtm(cvect, corpus)analyzer
- 단위 선택 {'word', 'char', 'char_wb'}, 기본값='word'
TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)는 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다.
TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다. 하지만 단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미한다. 이것을 DF(문서 빈도, document frequency)라고 하며, 이 값의 역수를 IDF(역문서 빈도, inverse document frequency)라고 한다. TF-IDF는 TF와 IDF를 곱한 값이다.
IDF 값은 문서군의 성격에 따라 결정된다. 예를 들어 '원자'라는 낱말은 일반적인 문서들 사이에서는 잘 나오지 않기 때문에 IDF 값이 높아지고 문서의 핵심어가 될 수 있지만, 원자에 대한 문서를 모아놓은 문서군의 경우 이 낱말은 상투어가 되어 각 문서들을 세분화하여 구분할 수 있는 다른 낱말들이 높은 가중치를 얻게 된다.(https://ko.wikipedia.org/wiki/Tf-idf)
TfidfVectorizer
TfidfVectorizer 는 사이킷런에서 TF-IDF 가중치를 적용한 단어 벡터를 만들 수 있는 방법이다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfvect.fit_transform(corpus)
display_transform_dtm(tfidfvect, corpus)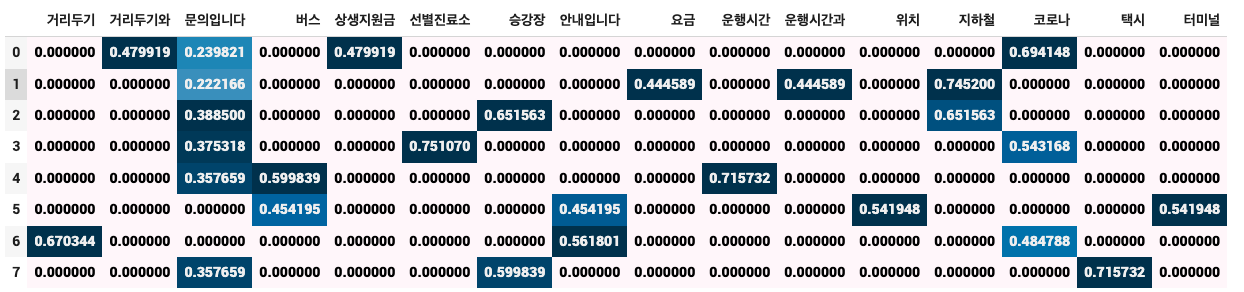
IDF
idf = tfidfvect.idf_
vocab = tfidfvect.get_feature_names_out()
idf_dict = dict(zip(vocab, idf))
print(idf_dict)
pd.Series(idf_dict).plot.barh()

TF-IDF 매개변수 (BOW와 동일)
- analyzer
- n-gram
- min_df, max_df
- max_features
- stop_words
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
NLP 단어 벡터화하기
BOW(bag of words)
- 가장 간단하지만 효과적이라 널리쓰이는 말뭉치 방법
- 각 단어가 이 말뭉치에 몇 번 나타나는지 파악(출현 회수 카운트)
- BOW는 단어의 순서가 완전히 무시 된다는 단점이 있다.
- it's bad, not good at all.
- it's good, not bad at all.
- 위 두 문장은 의미가 전혀 반대지만 완전히 동일하게 반환된다.
- 이를 보완하기 위해 n-gram을 사용한다. (n-gram은 n개의 토큰을 사용한다.)
CountVectorizer
CountVectorizer 는 사이킷런에서 제공하는 bag of words 를 만들 수 있는 방법이다
- 문서를 토큰 리스트로 변환한다.
- 각 문서에서 토큰의 출현 빈도를 센다.
- 각 문서를 BOW 인코딩 벡터로 변환한다.
- 매개 변수
analyzer : 단어, 문자 단위의 벡터화 방법 정의
ngram_range : BOW 단위 수 (1, 3) 이라면 1개~3개까지 토큰을 묶어서 벡터화
max_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 높은 용어(말뭉치 관련 불용어)는 제외 (기본값=1.0)
max_df = 0.90 : 문서의 90% 이상에 나타나는 단어 제외
max_df = 10 : 10개 이상의 문서에 나타나는 단어 제외
min_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 낮은 용어는 제외합니다. 컷오프라고도 합니다.(기본값=1.0)
min_df = 0.01 : 문서의 1% 미만으로 나타나는 단어 제외
min_df = 10 : 문서에 10개 미만으로 나타나는 단어 제외
stop_words : 불용어 정의from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()
cvect.fit_transform(corpus)✅ fit_transform 은 학습데이터에만 사용하고 예측 데이터에는 transform 을 사용해야 한다.
➡️ 예측 데이터에도 fit_transform 을 사용하게 된다면 서로 다른 단어사전으로 행렬을 만들게 되기 때문
dtm = cvect.fit_transform(corpus)# 단어 사전 보기
vocab = cvect.get_feature_names_out()
vocab
단어사전은 {"단어": 인덱스번호}
cvect.vocabulary_df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)# df_dtm.sum 으로 빈도수 합계 구하기
df_dtm.sum()매개 변수 들여다 보기
N-grams
- 토큰을 몇 개 사용할 것인지를 구분, 지정한 n개의 숫자 만큼의 토큰을 묶어서 사용한다.
- 예를 들어 (1, 1) 이라면 1개의 토큰을 (2, 3)이라면 2~3개의 토큰을 사용합니다.
- 기본값 = (1, 1)
- ngram_range(min_n, max_n)
cvect = CountVectorizer(ngram_range=(1, 2))
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
df_dtm# 모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수를 만들어 활용하기
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
return df_dtm.style.background_gradient()min_df
- 지정된 임계값보다 낮은 용어 무시
- 빈도가 매우 낮은 특이한 용어를 제거하는 데 사용
- 기본값=1, float으로 지정시 %만큼 제외
max_df
- 지정된 임계값보다 높은 용어 무시
- 너무 자주 사용되서 의미가 없는 용어 제거 (불용어 등)
- 기본값 =1
- ex) max_df = 0.89로 지정시 90% 등장하는 <불용어> 제외 가능
max_features
- 벡터라이저가 학습할 어휘의 양 제한
- corpus 중 빈도수가 높은 순으로 해당 개수만큼 추출
- 기본값 = None
Stop_words(불용어)
- 자주 등장하지만 문장 내에서 큰 의미를 갖지 않는 단어(관사, 전치사, 조사, 접속사 등)
- 도메인에 따라 불용어는 달라진다.
stop_words=["코로나", "문의입니다", "터미널", "택시"]
cvect = CountVectorizer(stop_words=stop_words)
display_transform_dtm(cvect, corpus)analyzer
- 단위 선택 {'word', 'char', 'char_wb'}, 기본값='word'
TF-IDF
TF-IDF(Term Frequency - Inverse Document Frequency)는 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치이다.
TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값으로, 이 값이 높을수록 문서에서 중요하다고 생각할 수 있다. 하지만 단어 자체가 문서군 내에서 자주 사용되는 경우, 이것은 그 단어가 흔하게 등장한다는 것을 의미한다. 이것을 DF(문서 빈도, document frequency)라고 하며, 이 값의 역수를 IDF(역문서 빈도, inverse document frequency)라고 한다. TF-IDF는 TF와 IDF를 곱한 값이다.
IDF 값은 문서군의 성격에 따라 결정된다. 예를 들어 '원자'라는 낱말은 일반적인 문서들 사이에서는 잘 나오지 않기 때문에 IDF 값이 높아지고 문서의 핵심어가 될 수 있지만, 원자에 대한 문서를 모아놓은 문서군의 경우 이 낱말은 상투어가 되어 각 문서들을 세분화하여 구분할 수 있는 다른 낱말들이 높은 가중치를 얻게 된다.(https://ko.wikipedia.org/wiki/Tf-idf)
TfidfVectorizer
TfidfVectorizer 는 사이킷런에서 TF-IDF 가중치를 적용한 단어 벡터를 만들 수 있는 방법이다.
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfvect.fit_transform(corpus)
display_transform_dtm(tfidfvect, corpus)IDF
idf = tfidfvect.idf_
vocab = tfidfvect.get_feature_names_out()
idf_dict = dict(zip(vocab, idf))
print(idf_dict)
pd.Series(idf_dict).plot.barh()TF-IDF 매개변수 (BOW와 동일)
- analyzer
- n-gram
- min_df, max_df
- max_features
- stop_words