
오늘의 회고
사실(Fact)
- Pandas 실습, Seaborn 시각화 실습
- 엔스컴 콰르텟 그리기
느낌(Feeling)
- 통계 이론과 용어에 대해 익숙하지 않아서 단순한 문법도 결과물이 어떤 것을 나타내는 지, 이해하는데 시간이 오래 걸려서 어려웠다.
- 시각화 결과가 제대로 나올땐 재밌고 신기했다.
교훈(Finding)
- 통계 관련 책을 읽어봐야겠다. (무료 ebook부터 꼼꼼히!)
- 오늘 내용을 잘 복습해봐야겠다.
- 오늘 배운 내용을 바탕으로 블로그명을 정할 수 있었다ㅎㅎ
Pandas 기본문법
데이터 프레임 (행과 열이 있는 구조)
컬럼 추가하기
df = pd.Dataframe()
df["컬럼명"] = ["A", "B", "C"]칼럼 -> 리스트로 전환하는 법 :
df["칼럼명"].tolist() # list(df["칼럼명"])과 동일하다데이터 지우는 법
df = df.drop("컬럼명", axis = 1)
# 데이터 지운후에 지운 값을 다시 변수에 할당해야 반영된다.
# axis 0:행, 1:컬럼을 의미한다.데이터프레임 기초
- df.info() 데이터 프레임의 요약 정보
- df.shape 데이터 프레임의 크기 (행, 열)
- df.dtypes 데이터의 타입
- df.columns = [바꿀 column] 컬럼명 바꾸기
- df.corr() 상관계수 보기
- df.describe() 데이터 프레임의 요약정보, 수치형 데이터의 기술통계 값
(평균, 표준편차, 최솟값, 최댓값 분산, 사분위수) - df.describe(include = "object") 범주형 데이터의 기술통계 값
(개수, 빈도, 고유값, 최빈값, 유일값)
여러개의 컬럼 가져오기
df[["컬럼명1, 컬럼명2]]
#리스트형으로 가져오기 위해 []로 한번 더 묶어줘야 한다행 가져오기
df.loc[i]loc와 iloc차이
- loc[0] 1개는 행 정보
- loc[0, 1] 두 개 들어가면 행, 열 정보이다
df.loc[0:2, ["컬럼명1", "컬럼명2"]] -> 요렇게도 가능 - 밸류값 그대로 가져오는 것이 loc
- iloc는 순서대로 값을 가져오고자 할때
인덱스 설정하기
df.set_index
df.reset_index
df.set_index( ).loc[ "유니크값을 가진 컬럼명"]
# 숫자 대신 문자를 인덱스로 활용하는 법특정 정보만 가져오기
df[df["컬럼명"].str.contains("특정정보")]
- 파이썬의 정규표현식에서는 |(파이프) 는 or를, &는 and를 의미한다.
- a또는 에이 검색은 "에이 | a" 로 가능
파생변수
- 기존 열에서 수정, 변경된 값으로 만들어진 새로운 열이라고 이해하였다
ex) 소문자 변경 df["새로운 열"] = df["기존 열"].str.lower()
기타 키워드
- np.nan type은 float
- NA: not available, not applicable의 약어
- 사분위수(Q1~Q4)
- method chaining: .을 통해 매서드를 계속 덧붙이는 것
- DF은 [[ ]] 대괄호가 두개!! 꼭 외우기
- Code of Conduct: 커뮤니티에서의 태도, 기능 비교는 좋지만 존중해야함
- 개발자에게는 문제해결능력이 중요! 다른 새로운 언어, 환경을 마주했을때 그 문제를 어떻게 해결해 나가는 지 과정이 중요하다
인코딩 방법
- UTF-8 사용, 엑셀 한글 등은 cp949라 깨질 수 있음 기사 읽어보기
- EUC-KR은 2,350자의 한글, CP949는 11,172자의 한글을 표현할 수 있다. 그러나 Java에서는 CP949와 MS949를 다르게 취급한다
- 전 세계적으로 사용되는 모든 문자 집합을 하나로 모아 탄생시킨 것이 유니코드이다.
- 이 중 ASCII와 호환이 가능하면서 유니코드를 표현할 수 있는 UTF-8 인코딩이 가장 많이 사용된다.
Seaborn 실습
- 엔스컴 콰르텟 Anscome 's Quartet
- 엔스컴 콰르텟 그래프 그리기 실습
https://ko.wikipedia.org/wiki/앤스컴_콰르텟
기술통계를 살펴보면 mean(평균), std(표준편차), corr(상관계수) 값이 매우 유사하다. (소숫점 이하의 근소한 차이)
seaborn 내장 데이터셋을 활용한다.
sns.load_dataset("anscombe")
일부 데이터만 확인하기 (sample)
df.sample(frac = 0.2, random_state = 42)- random_state: random seed값, 랜덤한 값을 고정시켜주는 것
- frac=0~1: 추출할 표본 비율
빈도수, 빈도수 비율 구하기 (value_counts)
# value_counts를 통해 dataset 의 빈도수 구하기
df["dataset"].value_counts()
# value_counts를 통해 dataset 의 빈도수 normalize로 비율 구하기
df["dataset"].value_counts(normalize=True) #한 개 변수에 대한 빈도수를 value count로 구한다Seaborn 시각화
Seaborn으로 그릴 수 있는 그래프들의 관계 (dogplot은 없다 :ㅇ)
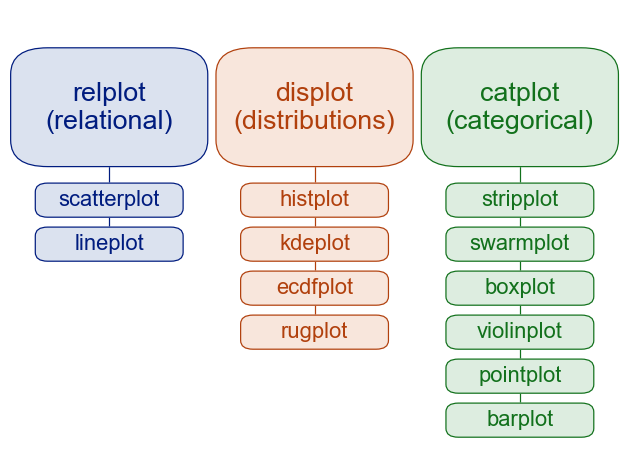
https://seaborn.pydata.org/tutorial/function_overview.html
- relplot: 두 가지 변수의 관계를 나타내기 위해 주로 사용
- displot : 변수 하나 혹은 두 개의 값 분포를 나타내기 위해 주로 사용
- catplot: 범주형 변수와 연속형 변수 간의 관계를 나타내기 위해 주로 사용
countplot 빈도수 카운트 그래프

barplot 막대그래프

- ci: int = 95, Confidence interval: 신뢰구간
violinplot: 분산 정보 포함

displot

그 밖에
- scatterplot
- regplot
- lmplot
- hist(히스토스램): 구간마다 빈도수 포함 (빈도 - bins)도수분포란? 정해진 계급에 변량이 분포되어 있는 정도를 표로 나타낸 것/ 어떤 기준에 의한 수의 분포
- kdeplot
커널 밀도 추정(kernal density estimation) 그래프로, 히스토그램이 절대량(count)을 표현한다면 kdeplotdms 상대량(비율)을 시각화 히스토그램과 마찬가지로 한개 혹은 두개의 변수에 대한 분포를 그릴 수 있음
- boxplot


출처_파이썬을 활용한 데이터.AI 분석 사례, 건강보험심사평가원, 2021
강의내용 출처는 멋쟁이사자처럼 AI스쿨 7기 박조은 강사님 (오늘코드) 입니다.