
오늘의 회고
- 사실(Fact): 캐글 자전거 수요 예측 실습
- 느낌(Feeling): 데이터EDA로 꼼꼼하게 살펴보면서 이상한 데이터를 찾는 게 재밌었다. 로그 개념이 아직 완전히 이해하기 어렵지만 사용하는 이유는 알 것 같다
- 교훈(Finding): 오늘 수업 복습 철저히! 특히 RMSLE!
Cross validation: 속도가 오래걸린다는 단점이 있기도 하지만 validation의 결과에 대한 신뢰가 중요할 때 사용한다.
hold out validation: 한번만 나눠서 학습하고 검증하기 때문에 빠르다는 장점이 있다. 하지만 신뢰가 떨어지는 단점이 있다.
경진대회 참가할때 꼼꼼히 확인할 것
- Data Fields (도메인 지식 있으면 좋음)
- evaluation 측정기준
- 무엇을 예측하는 문제인지
데이터 EDA과정
- 결측치, 이상치, 히스토그램 등 확인
- 이번 데이터의 wind speedmonth처럼 꼼꼼히 확인해야함
- 점수를 올리기 위해서는 EDA를 꼼꼼하게 하고 우리가 예측하고자 하는 정답이 어떤 피처에서 어떻게 다른 점이 있는지 특이한 점은 없는지 탐색해 보는게 중요하다
Bike Sharing Demand
https://www.kaggle.com/competitions/bike-sharing-demand/overview/evaluation
Data Fields
datetime - hourly date + timestamp
season - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday - whether the day is considered a holiday
workingday - whether the day is neither a weekend nor holiday
weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp - temperature in Celsius
atemp - "feels like" temperature in Celsius
humidity - relative humidity
windspeed - wind speed
casual - number of non-registered user rentals initiated
registered - number of registered user rentals initiated
count - number of total rentals"feels like" temperature in Celsius == 체감온도
casual: 회원가입 하지 않은 유저
registered: 회원 가입한 유저
측정기준
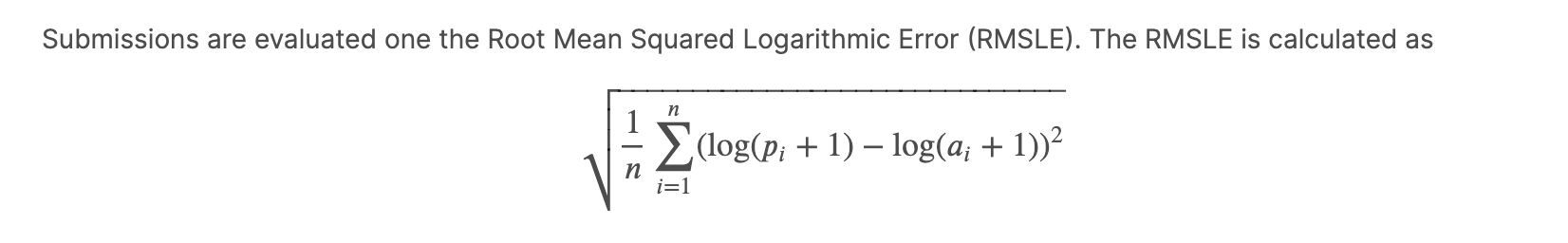
- RMSE와 차이
- logarithm?
- 회귀 모델
무엇을 예측하는 문제인지
시간대별 자전거 대여 수요 예측
You must predict the total count of bikes rented during each hour covered by the test set, using only information available prior to the rental period.

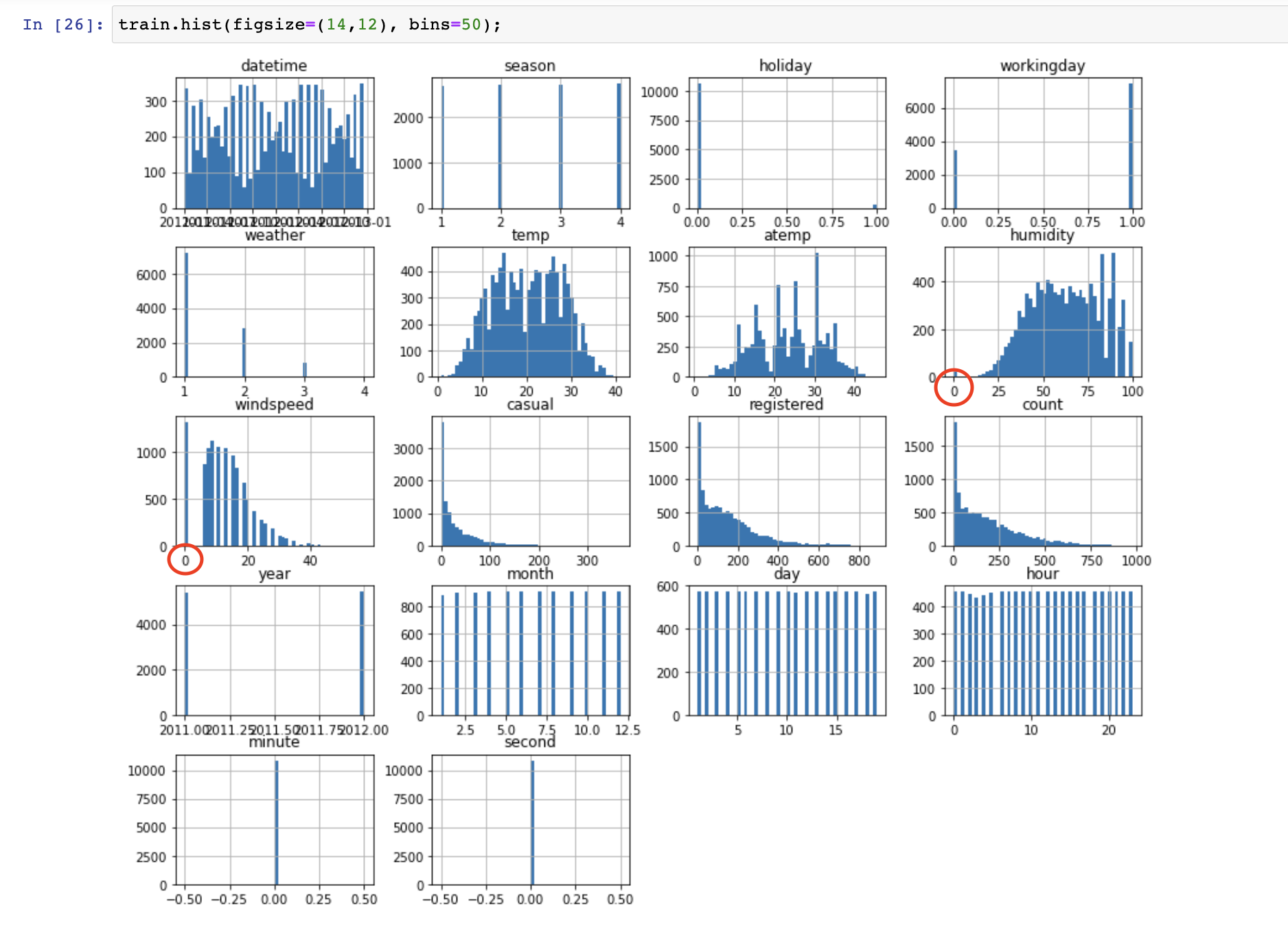
풍속과 습도
값이 0인 데이터 여러 개 발견
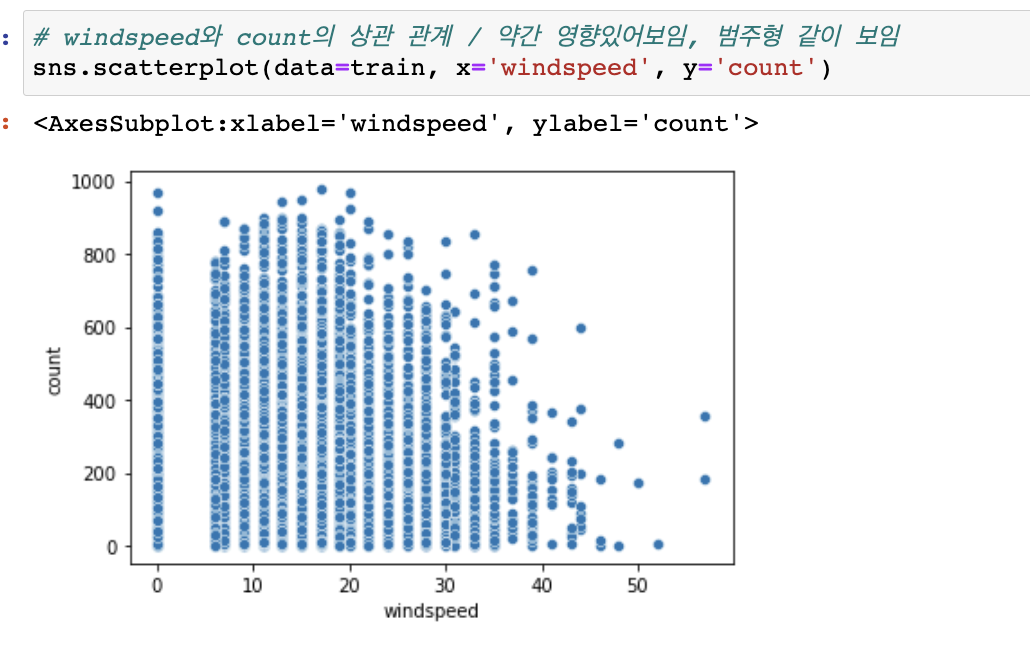
습도의 경우
결측치가 있어 보일때 만약 상관이 커보인다면 결측치를 전처리 해줄 수도 있으나 습도와 자전거 대여량은 상관이 없어보인다.
0이라는 결측치가 많지 않음
온도와 체감온도


EDA 결과 이상치 라기보다는, 8월 17일의 데이터 입력 오류로 판단된다.
날씨별 count의 수
3보다 4가 많아서 이상해보이지만, 알고보면 4인 데이터는 1개뿐이다

머신 러닝
# randomforest
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(max_depth=15, n_jobs=-1)
model교차 검증
from sklearn.model_selection import cross_val_predict
y_valid_pred = cross_val_predict(model, X_train, y_train, cv=5, n_jobs=-1, verbose=2)
y_valid_pred
MAE
모델의 예측값과 실제 값 차이의 절대값 평균
절대값을 취하기 때문에 가장 직관적임
MSE
모델의 예측값과 실제값 차이의 면적의(제곱)합
제곱을 하기 때문에 특이치에 민감하다.
RMSE
MSE에 루트를 씌운 값
RMSE를 사용하면 지표를 실제 값과 유사한 단위로 다시 변환하는 것이기 때문에 MSE보다 해석이 더 쉽다.
MAE보다 특이치에 Robust(강하다 ==덜 민감하다)
RMSLE
x 가 1보다 작으면 음수가 나오기 때문에 1을 더해서 1이하의 값이 나오지 않게 하기위해 1을 더한 후에 로그를 취한다.
log의 밑은 e로 자연상수이며 2.718281... 의 값을 가진다.
RMSLE는 실제값보다 예측값이 클떄보다, 실제값보다 예측값이 더 작을 때 (Under Estimation) 더 큰 패널티를 부여한다.
자전거 대여수는 대부분 작은 값에 몰려있기 떄문에 log를 취하고 계산하게 되면 오차가 큰 값보다 작은값에 더 패널티가 들어가게 된다.
즉, RMSE: 오차가 클수록 가중치를 주게 됨(오차 제곱의 효과) RMSLE: 오차가 작을수록 가중치를 주게 됨(로그의 효과)
데이터 전처리
dt 날짜 변수
train['datetime'] = pd.to_datetime(train['datetime'])
train["year"] = train["datetime"].dt.year
train["month"] = train["datetime"].dt.month
train["day"] = train["datetime"].dt.day
train["hour"] = train["datetime"].dt.hour
train["minute"] = train["datetime"].dt.minute
train["second"] = train["datetime"].dt.second피처 선택에서 중요했던 것들
1. train과 test 데이터가 day기준으로 나눠져 있어서 day는 피처로 의미 없었음
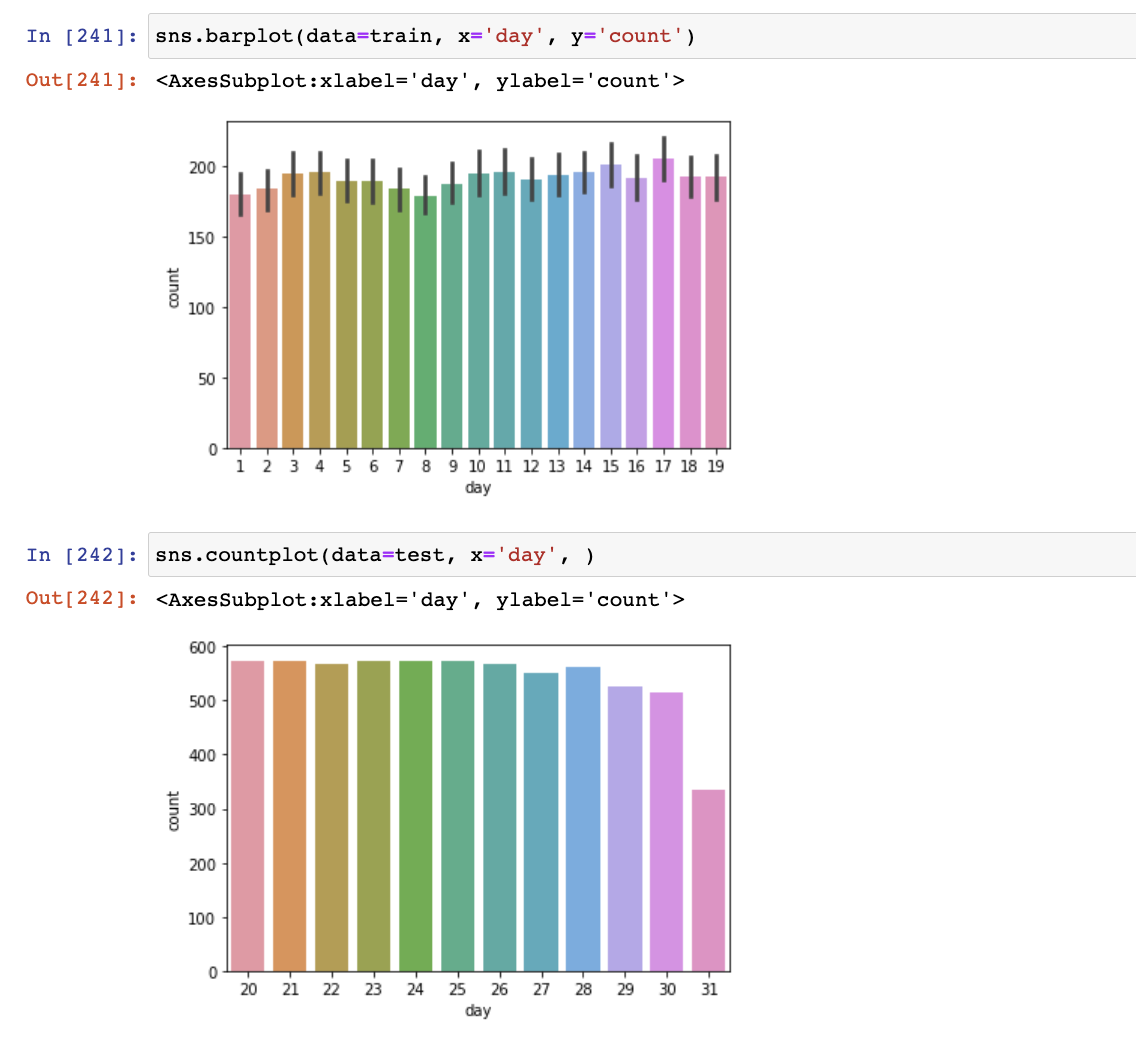
2. month
2011년과 2012년 데이터의 차이가 커서 month만으로 의미있는 결과 내기 어려움

따라서 'day' 와 'month'를 피처에서 제거한 것 만으로도 오차 크게 감소하였음 (0.48649 -> 0.44197)
캐글 제출 점수
(위 - 기본 모델, 아래 - 피처 엔지니어링 + 파라메터 튜닝 후)

