
오늘은 아주 오랜만에 인싸데이로 진행되서
오전엔 키워드 복습을 진행했다.
우리 조의 주제는 결정 트리(Decision Tree) 였고,
다른 조의 주제도 머신러닝 관련 주제라서 새롭게 알게된 내용을 정리해보려고 한다.
주제1. 결정트리 Decision Tree
결정트리란?
결정 트리는 분류와 회귀 문제에 널리 사용하는 모델이다. 결정 트리를 학습한다는 것은 정답에 가장 빨리 도달하는 예/아니오 질문 목록을 학습한다는 뜻이다. 트리를 만들 때 알고리즘은 가능한 모든 테스트에서 타깃 값에 대해 가장 많은 정보를 가진 것을 고른다. 일반적으로 트리 만들기를 모든 리프 노드가 순수 노드가 될 때까지 진행하면 모델이 매우 복잡해지고 훈련 데이터에 과대적합된다.

사진의 각 노드에 적힌 samples는 각 노드에 있는 샘플의 수를 나타내며 value는 클래스당 샘플의 수를 제공한다.
특성 중요도feature importance는 트리를 만드는 결정에 각 특성이 얼마나 중요한지를 평가하는 속성이다. 이 값은 0과 1 사이의 숫자로, 각 특성에 대해 0은 전혀 사용되지 않았다는 뜻이고 1은 완벽하게 타깃 클래스를 예측했다는 뜻이다. 특성 중요도의 전체 합은 1이다.
어떤 특성의 feature_importance_ 값이 낮다고 해서 이 특성이 유용하지 않다는 뜻은 아니다. 단지 트리가 그 특성을 선택하지 않았을 뿐이며 다른 특성이 동일한 정보를 지니고 있을 수도 있다.
의사결정 트리의 장단점
결정 트리에서 모델 복잡도를 조절하는 매개변수는 트리가 완전히 만들어지기 전에 멈추게 하는 사전 가지치기 매개변수이다. 보통은 사전 가지치기 방법 중 max_depth, max_leaf_nodes 또는 min_samples_leaf 중 하나만 지정해도 과대적합을 막는 데 충분하다.
결정 트리가 이전에 소개한 다른 알고리즘들보다 나은 점은 두 가지이다. 첫째, 비교적 작은 트리일 경우, 만들어진 모델을 쉽게 시각화할 수 있어서 비전문가도 이해하기 쉽다. 그리고 데이터의 스케일에 구애받지 않는다. 각 특성이 개별적으로 처리되어 데이터를 분할하는 데 데이터 스케일의 영향을 받지 않으므로 결정 트리에서는 특성의 정규화나 표준화 같은 전처리 과정이 필요 없다. 특히 특성의 스케일이 서로 다르거나 이진 특성과 연속적인 특성이 혼합되어 있을 때도 잘 작동한다.
결정 트리의 주요 단점은 사전 가지치기를 사용함에도 불구하고 과대적합되는 경향이 있어 일반화 성능이 좋지 않다는 것이다. 그래서 앙상블 방법을 단일 결정 트리의 대안으로 흔히 사용하기도 한다.
(출처_텐서 플로우 블로그 (Tensor ≈ Blog))
2.3.5 결정 트리
2.3.4 나이브 베이즈 분류기 | 목차 | 2.3.6 결정 트리의 앙상블 – 결정 트리decision tree는 분류와 회귀 문제에 널리 사용하는 모델입니다. 기본적으로 결정 트리는 결정에 다다르기 위해 예/아니오
tensorflow.blog
결정트리 과적합 방지하기
많은 규칙이 있다는 것은 곧 분류를 결정하는 방식이 ‘더욱 복잡해진다’는 뜻이며, 과적합으로 이어지기 쉽다. 즉, 트리의 깊이(depth)가 깊어질수록 결정 트리의 예측 성능이 저하될 가능성이 높다. 일부 이상치(Outlier) 데이터까지 분류하기 위해 분할이 자주 일어나서 결정 기준 경계가 매우 많아지기 때문이다. 결정 트리의 기본 하이퍼 파라미터 설정은 리프 노드 안에 데이터가 모두 균일하거나 하나만 존재해야 하는 엄격한 분할 기준으로 인해 결정 기준 경계가 많아지고 복잡해졌다. 이렇게 복잡한 모델은 학습 데이터 세트의 특성과 약간만 다른 형태의 데이터 세트를 예측하면 예측 정확도가 떨어지게 된다. min_samples_leaf=6을 설정해 6개 이하의 데이터는 리프 노드를 생성할 있도록 리프 노드 생성 규칙을 완화한 뒤 실행하면 좀 더 일반화된 분류 규칙에 따라 분류됐음을 알 수 있다. 본 option을 설정하는 게 모델의 성능을 좀 더 향상할 수 있다.
(출처_결정트리(DecisionTree)와 과적합에 대해: https://nicola-ml.tistory.com/93)
머신러닝 강좌 #12] 결정트리(DecisionTree)와 과적합에 대해
결정 트리는 ML알고리즘 중 직관적으로 이해하기 쉬운 알고리즘입니다. 규칙 노드(Decision Node)로 표시된 노드는 규칙 조건이 되는 것이고, 리프 노드(Leaf Node)로 표시된 노드는 결정된 클래스 값입
nicola-ml.tistory.com
Decision Tree의 과적합을 줄이기 위한 파라미터 튜닝
(1) max_depth 를 줄여서 트리의 깊이 제한
(2) min_samples_split 를 높여서 데이터가 분할하는데 필요한 샘플 데이터의 수를 높이기
(3) min_samples_leaf 를 높여서 말단 노드가 되는데 필요한 샘플 데이터의 수를 높이기
(4) max_features를 높여서 분할을 하는데 고려하는 feature의 수 제한하기
(출처_[Chapter 4. 분류] Decision Tree Classifier: https://injo.tistory.com/15)
파라메터
| min_samples_split | - 노드를 분할하기 위한 최소한의 샘플 데이터수 → 과적합을 제어하는데 사용 - Default = 2 → 작게 설정할 수록 분할 노드가 많아져 과적합 가능성 증가 |
| min_samples_leaf | - 리프노드가 되기 위해 필요한 최소한의 샘플 데이터수 - min_samples_split과 함께 과적합 제어 용도 - 불균형 데이터의 경우 특정 클래스의 데이터가 극도로 작을 수 있으므로 작게 설정 필요 |
| max_features | - 최적의 분할을 위해 고려할 최대 feature 개수 - Default = None → 데이터 세트의 모든 피처를 사용 - int형으로 지정 →피처 갯수 / float형으로 지정 →비중 - sqrt 또는 auto : 전체 피처 중 √(피처개수) 만큼 선정 - log : 전체 피처 중 log2(전체 피처 개수) 만큼 선정 |
| max_depth | - 트리의 최대 깊이 - default = None → 완벽하게 클래스 값이 결정될 때 까지 분할 또는 데이터 개수가 min_samples_split보다 작아질 때까지 분할 - 깊이가 깊어지면 과적합될 수 있으므로 적절히 제어 필요 |
| max_leaf_nodes | 리프노드의 최대 개수 |
(출처_[Chapter 4. 분류] Decision Tree Classifier: https://injo.tistory.com/15)
지니 불순도 측정
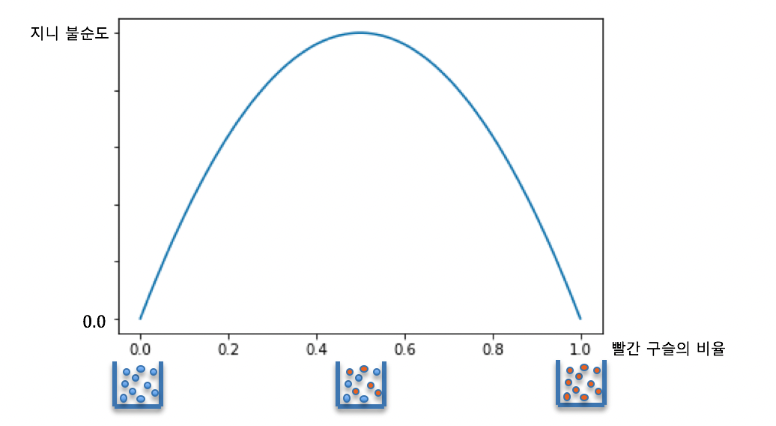
엔트로피: 무질서한 정도 / 높을 수록 불순도가 높고, 잘 분류되지 못했다는 뜻
지니계수 : 통계적 분산 정도를 정량화해서 표현한 값 / 0~1 사이 / 높을 수록 불순도가 높고, 잘 분류되지 못했다는 뜻
주제2. 배깅과 부스팅

앙상블 기법은 동일한 학습 알고리즘을 사용해서 여러 모델을 학습하는 개념이다. Bagging 과 Boosting 이 이에 해당한다.
Bagging == Bootstrap Aggregating
Bagging은 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계(Aggregating) 하는 방법이다.
알고리즘의 안정성과 정확성을 향상시키기 위해서 실행한다.
앙상블 기법은 높은 bias로 인한 Underfitting, 높은 Variance로 인한 Overfitting과 같은 오류를 최소화하는데 도움이 된다.
특히 Bagging은 각 샘플에서 나타난 결과를 일종의 중간값으로 맞추어 주기 때문에, Overfitting을 피할 수 있다.
대표적인 Bagging 알고리즘으로 RandomForest 모델이 있다. RandomForest는 여러 트리 모델을 결합하여 사용한다.
Boosting
Bagging이 일반적인 모델을 만드는데 집중되어있다면, Boosting은 맞추기 어려운 문제를 맞추는데 초점이 맞춰져 있다. Boosting도 Bagging과 동일하게 복원 랜덤 샘플링을 하지만, 가중치를 부여한다는 차이점이 있다. Bagging이 병렬로 학습하는 반면, Boosting은 순차적으로 학습시킨다. 학습이 끝나면 나온 결과에 따라 가중치가 재분배된다. 오답에 대해 높은 가중치를 부여하고, 정답에 대해 낮은 가중치를 부여하기 때문에 오답에 더욱 집중할 수 있게 된다. Boosting 기법의 경우, 정확도가 높게 나타난다. 하지만, 그만큼 Outlier에 취약하기도 하다. AdaBoost, XGBoost, GradientBoost 등 다양한 모델이 있다. 그 중에서도 XGBoost 모델은 강력한 성능을 보여주어, 최근 대부분의 Kaggle 대회 우승 알고리즘이기도 하다.
이미지 출처_https://towardsdatascience.com/ensemble-learning-bagging-boosting-3098079e5422
배깅과 부스팅 내용 출처_ https://swalloow.github.io/bagging-boosting/
주제3. 모델 성능 평가 지표

이미지_출처: https://bigdaheta.tistory.com/53
[머신러닝] 모델 성능 평가 지표 (회귀모델, 분류모델)
1. 모델 성능 평가 - 모델 성능평가란, 실제값과 모델에 의해 예측된 값을 비교하여 두 값의 차이(오차)를 구하는 것 - (실제값-예측값) =0 이 되면 오차가 없는 것으로, 모델이 값을 100% 잘 맞췄다
bigdaheta.tistory.com
R2 Score 결정계수
from sklearn.metrics import r2_score
r2_score(y_train, y_predict)회귀모델을 실습할때 수업시간에 활용했던 평가 지표
회귀 모델에서 독립 변수가 종속 변수를 얼마나 잘 설명했는지를 보여주는 지표이다.
일반적으로 피어슨 상관계수(Pearson Correlation Coefficient ,PCC)를 제곱한 값을 의미한다. (0~1 사이의 값을 가진다)
피어슨 상관계수가 +1일 때 완벽한 양의 상관관계, -1일 때 완벽한 음의 상관관계를 가진다.
따라서 상관관계가 높을수록 결정계수는 1에 근접해지며, 결정계수의 값이 클수록 회귀모형의 유용성이 높다고 할 수 있다.
(출처_https://aliencoder.tistory.com/34)
종합회고 및 목표
이번 주 종합 회고
- 매일 TIL 정리 밀리지 않기
- TIL은 성실하게, 나를 위한 기록으로 간단하게 적기
- 수업 파일을 깃허브에 공유할 수 없기때문에, 다른 걸로 커밋할 수 있는 방법 생각해보기
11월 목표
- 취준 대비 시작하기: 원하는 직무, 기업 찾아보기, 이력서 작성해보기
- 지금까지 했던 프로젝트 보기 좋게 정리 하기