
29일차 멋사 AI스쿨 main lecture by 박조은 강사님
오늘의 회고
사실(Fact): 머신러닝 트리 모델의 분류와 회귀, 랜덤 포레스트 실습
느낌(Feeling): 수업때 새로 나오는 개념을 이해하는 데 시간이 좀 걸린다. 집중이 잘 되지 않아 아쉬웠다.
교훈(Finding): 어제 과제를 하면서 머신러닝 실습 과정이 좀 이해가 되었다.
예습 동영상을 많이 봐서 다음 수업엔 더 많은 배경지식을 가지고 수업에 참여해야겠다.
분류: 랜덤포레스트 알고리즘 실습
어제 실습과 같은 당뇨병 데이터셋(data-diabetes) 사용
랜덤포레스트란?
https://ko.wikipedia.org/wiki/랜덤_포레스트
랜덤 포레스트의 가장 큰 특징은 랜덤성(randomness)에 의해 트리들이 서로 조금씩 다른 특성을 갖는다는 점이다.
이 특성은 각 트리들의 예측(prediction)들이 비상관화(decorrelation) 되게하며, 결과적으로 일반화(generalization) 성능을 향상시킨다. 또한, 랜덤화(randomization)는 포레스트가 노이즈가 포함된 데이터에 대해서도 강인하게 만들어 준다.
배깅(Bagging) 방식 - bootstrap aggregating 랜덤 추출할때 중복은 허용된다.
랜덤포레스트에서 가장 중요한 파라메터는 트리의 개수로, 기본값은 100개이다. (3000~5000개도 코랩에서 잘 돌아간다)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(random_state=42, min_samples_leaf=4, max_depth=8, n_estimators=500)주요 파라미터
n_estimators = 사용할 트리의 개수
n_jobs = 사용할 cpu 코어의 수, -1은 모든 코어 사용
max_depth = 랜덤포레스트에서 영향을 미치는 매개변수 중 하나의 트리에서 루트 노드부터 종단 노드까지 최대 몇 개의 노드를 거칠 것인지를 결정하는 것
회귀 실습
같은 당뇨병 데이터를 이용해서 이번엔 인슐린 수치를 예측하는 모델을 구현해보았다.
이때 원래 인슐린 데이터가 있는 행을 학습용으로, 수치가 0으로 사실상 Nan이나 다름 없는 행을 테스트용으로 사용하려고 하였다.
후자의 경우 정답이 없는데어떻게 해야 주어진 Train 데이터 내에서 학습량을 늘릴 수 있을까?
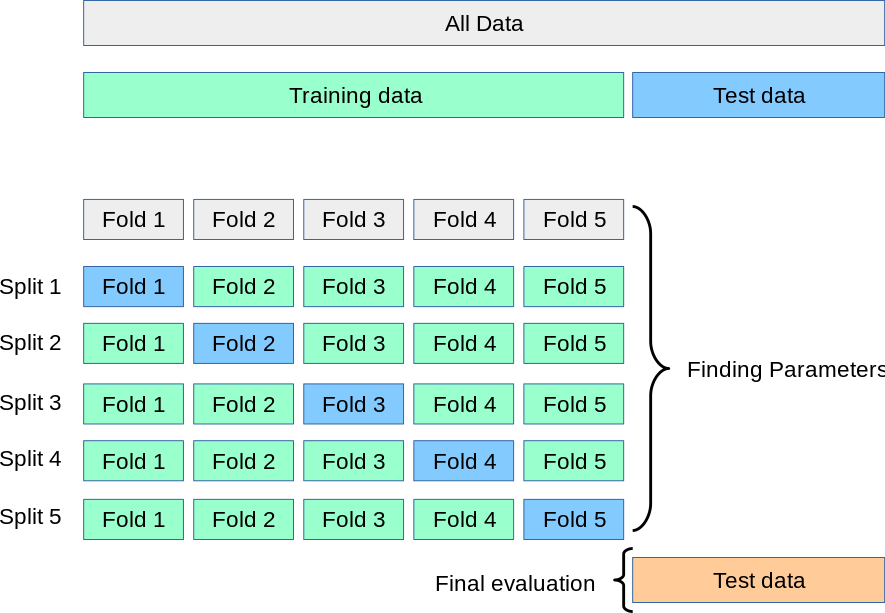
교차 검증 (cross validation) 활용
# model_selection의 cross_val_predict 로 cv로 조각을 나눠 valid 데이터의 학습결과 측정하기
from sklearn.model_selection import cross_val_predict
y_predict = cross_val_predict(model, X_train, y_train, cv=5, n_jobs=-1, verbose=2)
y_predict[:5]k-fold Cross Validation
- 모든 데이터가 최소 한 번은 검증 셋으로 쓰이도록 하기 위해 사용하는 방법이다.
- 데이터가 잘 훈련되었는지 검증하는 절차가 필수지만 데이터가 적은 경우에는 어렵다.
- fold의 갯수만큼 학습을 하게 된다.
- fold의 갯수만큼 학습을 하기 때문에 오래 걸리는 단점이 있다.
시각화로 실제값과 예측값 차이 비교해보기
sns.regplot(x= y_train, y= y_predict)
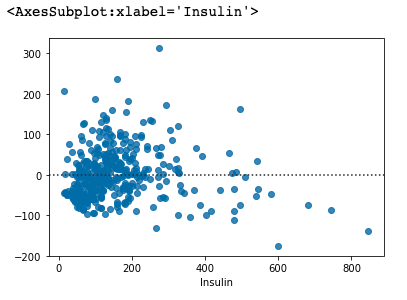
# residplot 으로 잔차(오차값)을 시각화 합니다.
sns.residplot(x= y_train, y= y_predict)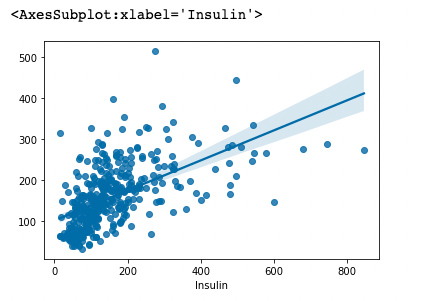
R2 score
# r2_score 를 구합니다. 1에 가까울때 best
from sklearn.metrics import r2_score
r2_score(y_train, y_predict)오차의 절대값 구하기
error = abs(y_train - y_predict)
sns.displot(error, aspect=5)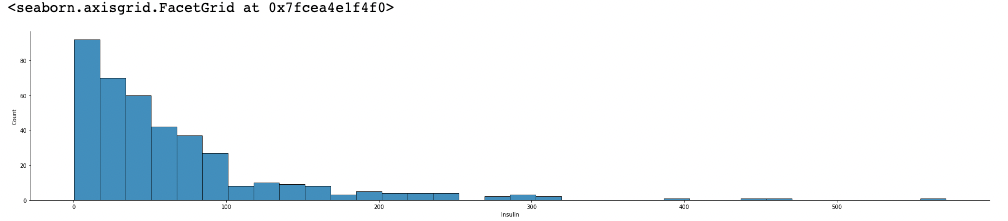
다음시간에 배울 예정: 오차의 절대값의 합을 구하는 평가 지표 Mean Absolute Error(MAE)