
오늘의 회고
사실(Fact) : seaborn 범주형 변수 시각화 실습, FinanceDataReader 실습, 네이버 금융 뉴스 웹크롤링 실습
느낌(Feeling) : Seaborn과 Pandas dataframe에 좀 익숙해진 것 같다. 코드가 이제 낯설게 보이지 않는다. 근데 크롤링을 해보니 또 다시 새로웠다.
교훈(Finding) : seaborn example다른 그래프도 읽어보고 그려봐야겠다. 웹크롤링 부분 다시 자세히 복습해봐야겠다.
범주형 데이터 EDA, Seaborn
# mpg 데이터셋을 불러옵니다.
df = sns.load_dataset("mpg")
df.shape
# shape는 어트리뷰트라서 ()를 안붙여도 된다. 매서드가 아니다
df.head()
df.tail()
df.info()기술통계 보기
# describe 를 통해 범주형 변수에 대한 기술통계를 보기
df.describe(include="object")
#object대신 np.int64 ... 가능
df.describe(exclude="object")
df.describe(include="all")

범주형 데이터라고 해서 꼭 object 형식으로만 있는 건 아니다.
bool, int, float으로 되어 있을 수도 있다.
⇒ 히스토그램 시각화를 해봤을때 이가 빠져있고 데이터가 떨어져있다
범주형 데이터 유일값, 유일값의 빈도수
df[”cylinders”].unique()
# nunique 값 구하기
df.nunique()unique()는 series 타입만 가능하고
nunique()는 dataframe 타입만 가능하다 → document참고

빈도수 시각화하기 (countplot)
Seaborn의 특징 통계적인 연산 제공, 빈도수를 나타낸다
sns.countplot(data = df, x = "origin")

1개 변수의 빈도수 구하기(value_counts)
df["origin"].value_counts()

2개 이상의 변수에 대한 빈도수 구하기 - crosstab 활용
# pd.crosstab 으로 시각화한 값 직접 구하기
pd.crosstab(index=df["origin"], columns = df["cylinders"])
같은 빈도수 countplot 시각화

Group by를 통한 연산
# groupby를 통해 origin 별로 그룹화 하고 mpg 의 평균 구하기
# df.groupby("origin")["mpg"].mean() - 시리즈 자료형
df.groupby("origin")[["mpg"]].mean() # - 데이터 프레임Pivot table을 통한 연산
# pivot_table 로 같은 값 구하기 , 기본값은 mean
pd.pivot_table(data=df, index="origin", values = "mpg")
# groupby 를 통해 위 시각화에 대한 값을 구하기
df.groupby(by=["origin","cylinders"])[["mpg"]].mean()pivot 과 pivot table의 차이
- pivot() 은 형태만 변경하고 연산을 하는 기능이 없다.
- 연산을 하기 위해서는 pivot_table()을 사용해야 한다.
- 평균계산: 지정하지 않아도 기본값이 평균, AggFuncType="mean”
# pivot_table 를 통해 위 시각화에 대한 값을 구하기
pd.pivot_table(data=df, index="origin", columns = "cylinders", values = "mpg")Dataframe의 unstacking
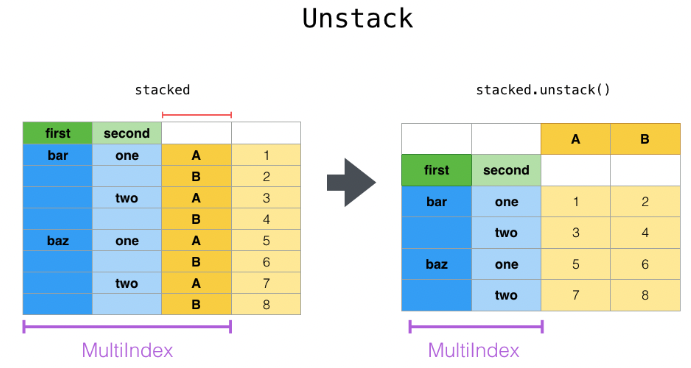
https://pandas.pydata.org/docs/user_guide/reshaping.html
df.groupby(by=["origin","cylinders"])[["mpg"]].mean().unstack()
- 마지막 인덱스의 값을 컬럼으로 끌어올린다
- unstack(”인덱스값”)을 쓰면 해당 인덱스값을 컬럼으로 끌어올린다
- 숫자를 쓰면 0을 쓰면 가장 앞의 인덱스를 컬럼으로 끌어올린다
Boxplot과 사분위수
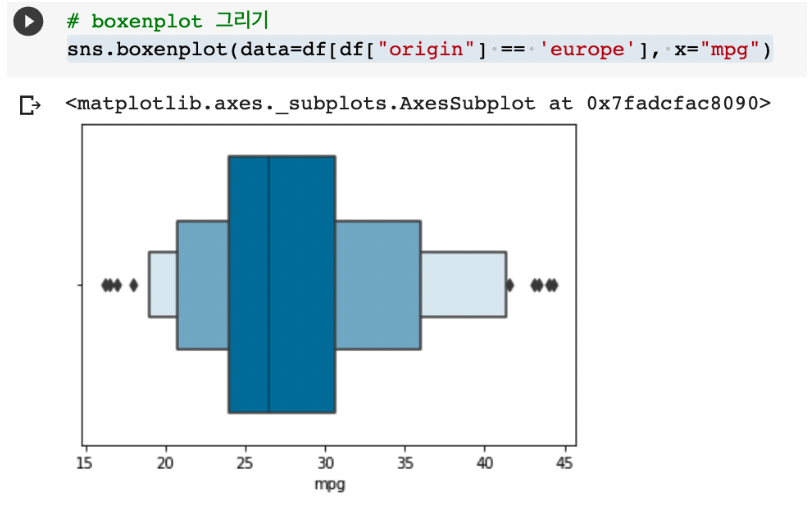
# boxplot 으로 origin 별 mpg 의 기술통계 값 구하기
sns.boxplot(data=df, x="origin", y= "mpg" )박스플롯 이해하기
- 상자수염그림이라고 불림
- 5가지 요약수치 표현
- 최솟값, Q1(하위25%), Q3(상위25%), Q2(중앙값), 최댓값
- 이상값: Q3 보다 1.5 IQR 이상 초과하는 값과 Q1보다 1.5 IQR 이상 미달하는 값은 점이나, 원, 별표 등으로 따로 표시한다.
# IQR, 이상치를 제외한 최댓값, 최솟값 구하기
Q3 = eu["75%"]
Q1 = eu["25%"]
IQR = Q3 - Q1
OUT_MAX = (1.5*IQR) + Q3
OUT_MIN = Q1 - (1.5*IQR)
Q3, Q1, IQR, OUT_MAX, OUT_MINBoxenplot
사분위 + 분포
scatterplot
- 변수 간 상관관계를 파악하기 어렵고, 점이 겹쳐 보여 명확하지 않고 빈도수를 알기 어렵다
- scatterplot대신 stripplot, swarmplot 사용
- Catplot의 기본값은 stripplot
- catplot은 서브플롯을 제공 col, col_wrap으로 쓴 것이 서브 플롯이다.
# catplot
plt.figure(figsize=(12,4))
sns.catplot(data=df, x="origin",y="mpg")
#기본값이 stripplot# catplot 으로 countplot그리기
sns.catplot(data=df, x="origin", kind="count", col="cylinders",col_wrap=3)
count는 x,y 중 하나만 써야한다. 나머지는 빈도수를 채워넣기 떄문웹 데이터 수집
- 추상화된 도구를 통한 데이터 수집 이해하기
- 저작권, 크롤링과 스크래핑의 차이 이해
- FinanceDataReader실습
KRXStockListing KRX상장 회사 목록 가져오기
-저작권, 크롤링과 스크래핑의 차이 이해, 크롤링 분쟁사례
자세한 내용은 웹크롤링 게시물에 작성했다.
강의 내용 출처_멋쟁이사자처럼 AI School 오늘코드 박조은 강사