221013 AI스쿨 TIL 의약품처방정보 EDA
20일차 멋사 AI스쿨 main lecture by 박조은 강사님

Seaborn 복습 https://seaborn.pydata.org/tutorial.html
relplot, displot, catplot 큰 범주는 외우기!
한글폰트 적용 설정
import koreanize_matplotlib
# 그래프에 retina display 적용
%config InlineBackend.figure_format = 'retina'
# 제대로 적용 되었는지 확인해보기
pd.Series([1,-1]).plot(title="한글")
의약품 처방데이터 분석
(100만명의 데이터 중 33만명 파일 활용)
csv 파일 위치 찾아서 불러오기 (glob)
from glob import glob
# glob("data/HP_*.csv") 데이터 폴더에 넣은 경우
file_name = glob("HP_*.CSV")raw = pd.read_csv(file_name[2], encoding="cp949")
표본 추출
데이터가 너무 커서 만명만 샘플링해서 사용 (np.random.choice)
# np.random.choice 를 통해 10000 명 샘플링
# 중복을 방지하려고 unique에서 돌림
rng = np.random.default_rng(42)
sample_no = np.random.choice(raw['가입자 일련번호'].unique(), size=10000)
# isin으로 샘플링한 가입자 일련번호 데이터만 추출하기
df_temp = raw[raw["가입자 일련번호"].isin(sample_no)]랜덤 값을 고정시키기
- 판다스: random_state = 42
- 넘파이: np.random.seed(42) <- 최근에는 권장하지 않는 방식
- 넘파이: rng = np.random.default_rng(42) <- 권장하는 방법
공식문서 참고 Random Generator https://numpy.org/doc/stable/reference/random/generator.html
랜덤 추출 후 sample데이터로 저장하기
데이터 전처리
- 결측치 처리
- 사용하지 않는 열 삭제
- 파생변수 만들기
- 월, 일, 요일 datetime .dt
- 코드에 맞는 코드명 연결하기
- 코드 처리되어있는 이유? 데이터 용량 줄이고, 인코딩 에러 방지를 위해서
<키워드>
pd.to_datetime()
리스트 컴프리헨션
딕셔너리 컴프리헨션
lambda
merge (on, how)
df = df.merge(df_table, on="제형코드", how="left")map
# 딕셔너리가 정의되었다면 lambda를 사용하지 않아도 된다.
df['시도명'] = df["시도코드"].map(city_name)
# map대신 replace도 가능
df['시도명'] = df["시도코드"].replace(city_name)to_dict
dict_d = df_table.set_index("제형코드")["제형명칭"].to_dict()기술통계
df.describe().T : 행렬 전치해서 확인하기

기술통계 수치를 참고해서 특정 조건 만족하는 행 찾기 (ex. max 참고해서 가장 비싼 금액의 약품코드 찾기)
상관분석
피어슨 상관계수 (-1부터 1까지)
값은 X 와 Y 가 완전히 동일하면 +1, 전혀 다르면 0, 반대방향으로 완전히 동일 하면 –1 을 가진다.
시각화
Seaborn
heatmap (mask 기능)
- # np.ones(df_cor.shape)
- # np.ones_like(df_cor)
- np.triu(np.ones_like(df_cor))
- np.tril(np.ones_like(df_cor))
vmin=-1, vmax=0.5 색상 농도 조절

countplot (빈도수) 정렬 참고
plt.figure(figsize=(20, 4))
sns.countplot(data=df.sort_values("연령대코드(5세단위)"), x="연령대")
barplot
# barplot 으로 연령대별 평균 단가를 시각화 합니다.
plt.figure(figsize=(20, 4))
sns.barplot(data=df,x="연령대",y="단가",order=age_dict.values(), ci=None)
# ci 오류가 난다면 errorbar=None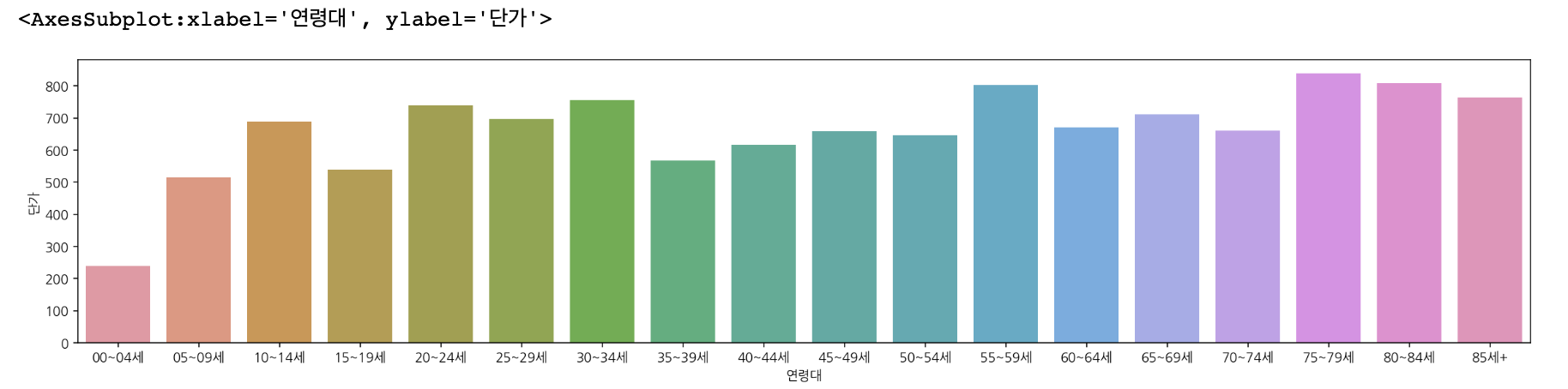
피벗테이블
group by 와 pivot_table
아래 3줄은 다 같은 결과
df.groupby(["연령대","성별"])["금액"].sum().unstack().plot.bar(figsize=(10,4))
df.pivot_table(index = ["연령대","성별"], values = "금액", aggfunc=sum).unstack().plot.bar(figsize=(10,4))
pd.pivot_table(df, index = "연령대", columns="성별", values = "금액", aggfunc=sum).plot.bar(figsize=(10,4))
