STUDY/머신러닝 | 딥러닝
자연어처리(NLP) 정리(2) - 문자 전처리(정규표현식 등)
둥둥런
2022. 12. 16. 16:43
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료입니다.
사용 데이터셋 출처:
- 뉴스 토픽 분류 AI 경진대회 - DACON
- KLUE Benchmark(https://klue-benchmark.com/)
문자 길이 세기

- len 문장 길이
- word_count 단어 수
- unique_word_count 중복 제거 단어수
# apply, lambda를 통해 문자, 단어 빈도수 파생변수 만들기
# df["len"] = df["title"].map(lambda x: len(x))
df["len"] = df["title"].str.len()
df["word_count"] = df["title"].map(lambda x : len(x.split()))
# 형태소 분석기를 사용하면 단어의 수를 셀때 중복을 더 제거할 수 있지만 여기에서는 우선 띄어쓰기 기준
df["unique_word_count"] = df["title"].map(lambda x : len(set(x.split())))
df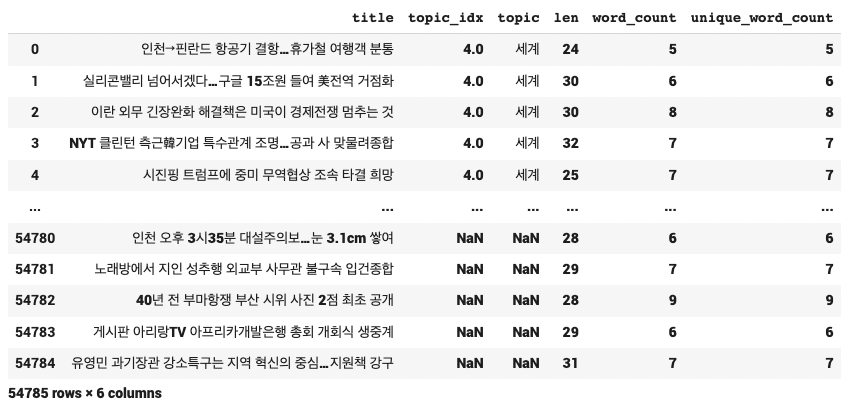
정규표현식
https://ko.wikipedia.org/wiki/%EC%A0%95%EA%B7%9C_%ED%91%9C%ED%98%84%EC%8B%9D
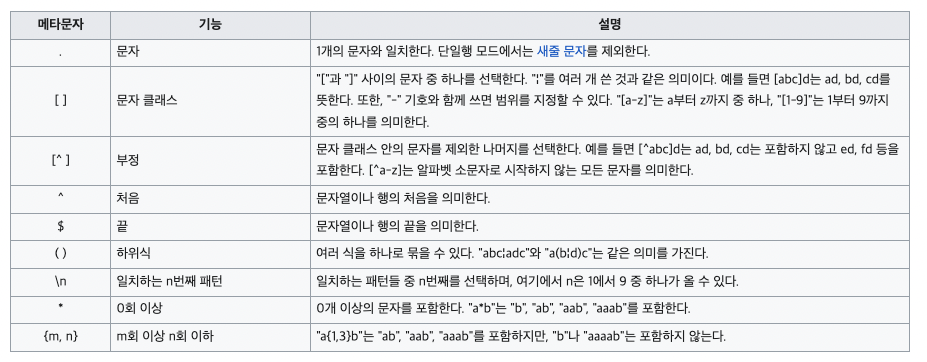
숫자 제거
import re
# re.sub(pattern, repl, string, count=0, flags=0)
re.sub("[0-9]", "", "12월 13일 눈이 내립니다.")df["title"].map(lambda x : re.sub("[0-9]", "", x))# 판다스의 str.replace 기능을 통해 제거
df["title"] = df["title"].str.replace("[0-9]", "", regex=True)특수 문자 제거
# 특수 문자 제거 시 구두점 참고
import string
punct = string.punctuation
punct!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~
# 특수 문자 사용시 정규표현식에서 메타 문자로 특별한 의미를 갖기 때문에 역슬래시를 통해 예외처리를 해주어야 한다
# [!\"\$\*] 일부 특수문자 제거 연습
df["title"] = df["title"].str.replace("[!\"\$\*]", "", regex=True)영문자 소문자/대문자로 변경
df["title"] = df["title"].str.lower()
df["title"] = df["title"].str.upper()
한글, 영문과 공백만 남기고 모두 제거
df["title"] = df["title"].str.replace(
"[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]", "", regex=True)공백 여러개를 하나로
# 공백 여러 개 전처리 예시
re.sub("[\s]+", " ", "공백 전처리")
# 여러 개의 공백을 하나의 공백으로 치환해 줍니다.
df["title"] = df["title"].str.replace("[\s]+", " ", regex=True)# ㅋㅋㅋㅋㅋ 를 ㅋ 로 변경하기
re.sub("[ㅋ]+", "ㅋ", "ㅋㅋㅋㅋㅋ")불용어 제거
stop word를 제외하고, meaningful words만 남겨서 join
# 불용어 제거
def remove_stopwords(text):
tokens = text.split(' ')
stops = [ '합니다', '하는', '할', '하고', '한다',
'그리고', '입니다', '그', '등', '이런', '및','제', '더']
meaningful_words = [w for w in tokens if not w in stops]
return ' '.join(meaningful_words)# map을 사용하여 불용어 제거하기
df["title"] = df["title"].map(remove_stopwords)
df["title"]
워드 클라우드
from wordcloud import WordCloud
def display_word_cloud(data, width=1200, height=500):
word_draw = WordCloud(
# r(raw) \n 이 있을 때 경로에서 줄바꿈을 하는 문제 등이 발생하기 때문에 그 텍스트 그대로 읽어오게 합니다.
font_path=r"/Library/Fonts/NanumBarunGothic.ttf",
width=width, height=height,
stopwords=["합니다", "입니다"],
background_color="white",
random_state=42
)
word_draw.generate(data)
plt.figure(figsize=(15, 7))
plt.imshow(word_draw)
plt.axis("off")
plt.show()🔽 예시
